На данный момент мало кто задумывается над тем, как же работает сжатие файлов. По сравнению с прошлым пользование персональным компьютером стало намного проще. И практически каждый человек, работающий с файловой системой, пользуется архивами. Но мало кто задумывается над тем, как они работают и по какому принципу происходит сжатие файлов. Самым первым вариантом этого процесса стали коды Хаффмана, и их используют по сей день в различных популярных архиваторах. Многие пользователи даже не задумываются, насколько просто происходит сжатие файла и по какой схеме это работает. В данной статье мы рассмотрим, как происходит сжатие, какие нюансы помогают ускорить и упростить процесс кодирования, а также разберемся, в чем принцип построения дерева кодирования.
История алгоритма
Самым первым алгоритмом проведения эффективного кодирования электронной информации стал код, предложенный Хаффманом еще в середине двадцатого века, а именно в 1952 году. Именно он на данный момент является основным базовым элементом большинства программ, созданных для сжатия информации. На данный момент одними из самых популярных источников, использующих этот код, являются архивы ZIP, ARJ, RAR и многие другие.
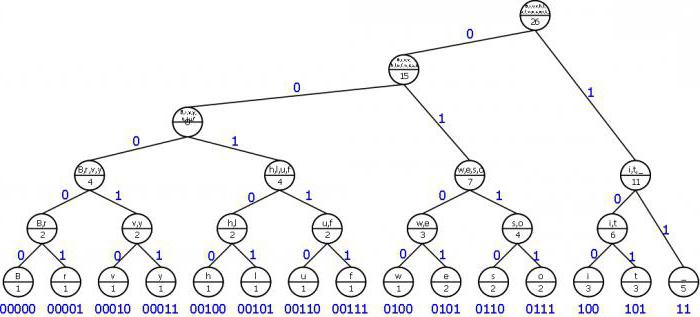
Принцип эффективного кодирования
В основу алгоритма по Хаффману входит схема, позволяющая заменить самые вероятные, чаще всего встречающиеся символы кодами двоичной системы. А те, которые встречаются реже, заменяются более длинными кодами. Переход на длинные коды Хаффмана происходит только после того, как система использует все минимальные значения. Такая методика позволяет минимизировать длину кода на каждый символ исходного сообщения в целом.
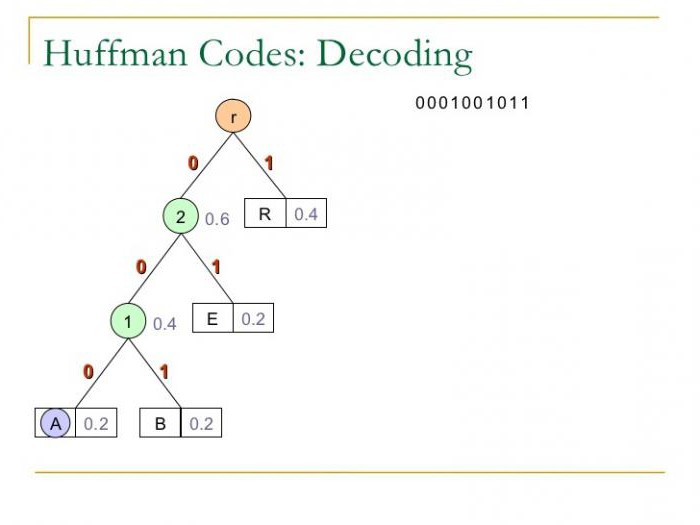
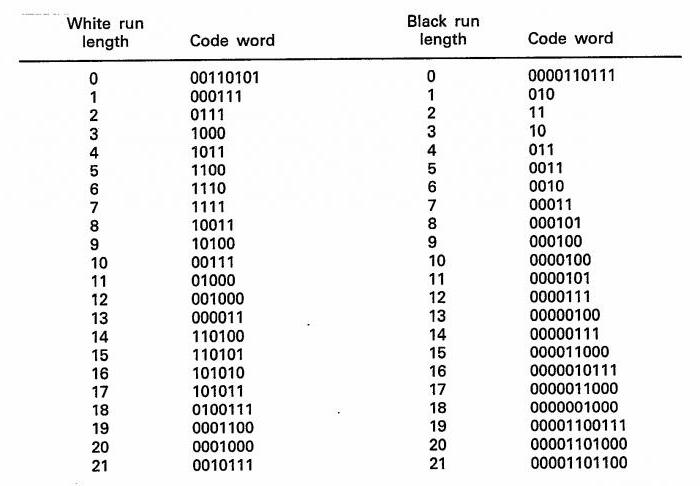
Код Хаффмана, пример
Чтобы проиллюстрировать алгоритм, возьмем графический вариант построения кодового дерева. Чтобы использование этого способа было эффективным, стоит уточнить определение некоторых значений, необходимых для понятия данного способа. Совокупность множества дуг и узлов, которые направлены от узла к узлу, принято называть графом. Само дерево является графом с набором определенных свойств:
- в каждый узел может входить не больше одной из дуг;
- один из узлов должен быть корнем дерева, то есть в него не должны входить дуги вообще;
- если от корня начать перемещение по дугам, этот процесс должен позволять попасть совершенно в любой из узлов.
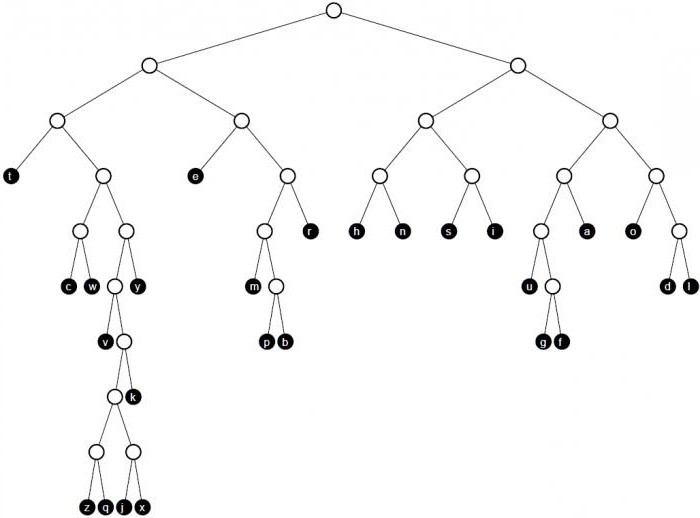
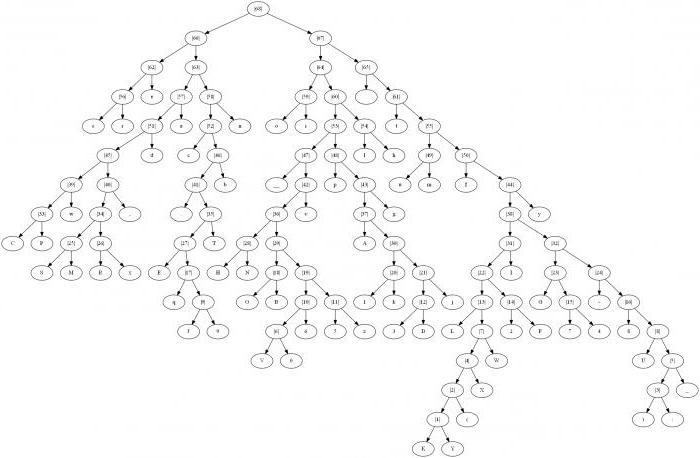
Алгоритм построения дерева по Хаффману
Построение кода Хаффмана делается из букв входного алфавита. Образуется список тех узлов, которые свободны в будущем кодовом дереве. Вес каждого узла в этом списке должен быть таким же, как и вероятность возникновения буквы сообщения, соответствующей этому узлу. При этом среди нескольких свободных узлов будущего дерева выбирается тот, который весит меньше всего. При этом если минимальные показатели наблюдаются в нескольких узлах, то можно свободно выбирать любую из пар.
Повышение эффективности сжатия
Чтобы повысить эффективность сжатия, нужно во время построения дерева кода использовать все данные относительно вероятности появления букв в конкретном файле, прикрепленном к дереву, и не допускать того, чтобы они были раскиданы по большому количеству текстовых документов. Если предварительно пройтись по этому файлу, можно сразу просчитать статистику того, насколько часто встречаются буквы из объекта, подлежащего сжиманию.
Ускорение процесса сжатия
Чтобы ускорить работу алгоритма, определение букв нужно проводить не по показателям вероятности появления той или иной буквы, а по частоте ее встречаемости. Благодаря этому алгоритм становится проще, и работа с ним значительно ускоряется. Также это позволяет избежать операций, связанных с плавающими запятыми и делением.
Заключение
Коды Хаффмана - простой и давно созданный алгоритм, который до сих пор используется многими известными программами и компаниями. Его простота и понятность позволяют добиться эффективных результатов сжатия файлов любых объемов и значительно уменьшить занимаемое ими место на диске хранения. Иными словами, алгоритм Хаффмана – давно изученная и проработанная схема, актуальность которой не уменьшается по сей день.