














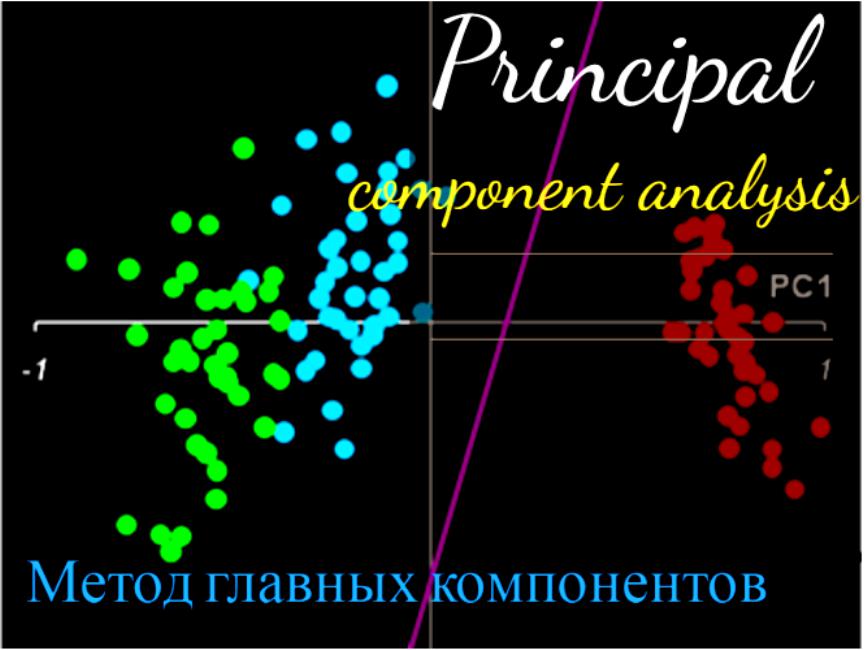
Метод главных компонентов (английский - principal component analysis, PCA) упрощает сложность высокоразмерных данных, сохраняя тенденции и шаблоны. Он делает это, преобразуя данные в меньшие размеры, которые действуют, как резюме функций. Такие данные очень распространены в разных отраслях науки и техники, и возникают, когда для каждого образца измеряются несколько признаков, например, таких как экспрессия многих видов. Подобный тип данных представляет проблемы, вызванные повышенной частотой ошибок из-за множественной коррекции данных.
Метод похож на кластеризацию - находит шаблоны без ссылок и анализирует их, проверяя, взяты ли образцы из разных групп исследования, и имеют ли они существенные различия. Как и во всех статистических методах, его можно применить неправильно. Масштабирование переменных может привести к разным результатам анализа, и очень важно, чтобы оно не корректировалось, на предмет соответствия предыдущему значению данных.
Цели анализа компонентов
Основная цель метода - обнаружить и уменьшить размерность набора данных, определить новые значимые базовые переменные. Для этого предлагается использовать специальные инструменты, например, собрать многомерные данные в матрице данных TableOfReal, в которой строки связаны со случаями и столбцами переменных. Поэтому TableOfReal интерпретируется как векторы данных numberOfRows, каждый вектор которых имеет число элементов Columns.
Традиционно метод главных компонентов выполняется по ковариационной матрице или по корреляционной матрице, которые можно вычислить из матрицы данных. Ковариационная матрица содержит масштабированные суммы квадратов и кросс-произведений. Корреляционная матрица подобна ковариационной матрице, но в ней сначала переменные, то есть столбцы, были стандартизованы. Вначале придется стандартизировать данные, если дисперсии или единицы измерения переменных сильно отличаются. Чтобы выполнить анализ, выбирают матрицу данных TabelOfReal в списке объектов и даже нажимают перейти.
Это приведет к появлению нового объекта в списке объектов по методу главных компонент. Теперь можно составить график кривых собственных значений, чтобы получить представление о важности каждого. И также программа может предложить действие: получить долю дисперсии или проверить равенство числа собственных значений и получить их равенство. Поскольку компоненты получены путем решения конкретной задачи оптимизации, у них есть некоторые «встроенные» свойства, например, максимальная изменчивость. Кроме того, существует ряд других их свойств, которые могут обеспечить факторный анализ:
- дисперсию каждого, при этом доля полной дисперсии исходных переменных задается собственными значениями;
- вычисления оценки, которые иллюстрируют значение каждого компонента при наблюдении;
- получение нагрузок, которые описывают корреляцию между каждым компонентом и каждой переменной;
- корреляцию между исходными переменными, воспроизведенными с помощью р–компонента;
- воспроизведения исходных данных могут быть воспроизведены с р–компонентов;
- «поворот» компонентов, чтобы повысить их интерпретируемость.
Выбор количества точек хранения
Существует два способа выбрать необходимое количество компонентов для хранения. Оба метода основаны на отношениях между собственными значениями. Для этого рекомендуется построить график значений. Если точки на графике имеют тенденцию выравниваться и достаточно близки к нулю, то их можно игнорировать. Ограничивают количество компонентов до числа, на которое приходится определенная доля общей дисперсии. Например, если пользователя удовлетворяет 95% от общей дисперсии - получают количество компонентов (VAF) 0.95.
Основные компоненты получают проектированием многомерного статистического анализа метода главных компонентов datavectors на пространстве собственных векторов. Это можно сделать двумя способами - непосредственно из TableOfReal без предварительного формирования PCA объекта и затем можно отобразить конфигурацию или ее номера. Выбрать объект и TableOfReal вместе и «Конфигурация», таким образом, выполняется анализ в собственном окружении компонентов.
Если стартовая точка оказывается симметричной матрицей, например, ковариационной, сначала выполняют сокращение до формы, а затем алгоритм QL с неявными сдвигами. Если же наоборот и отправная точка является матрица данных, то нельзя формировать матрицу с суммами квадратов. Вместо этого, переходят от численно более стабильного способа, и образуют разложения по сингулярным значениям. Тогда матрица будет содержать собственные векторы, а квадратные диагональные элементы - собственные значения.
Виды линейных комбинаций
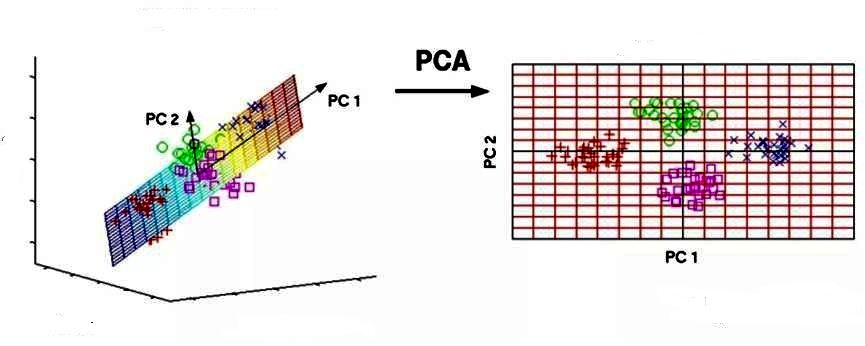
Основным компонентом является нормализованная линейная комбинация исходных предикторов в наборе данных по методу главных компонент для чайников. На изображении выше PC1 и PC2 являются основными компонентами. Допустим, есть ряд предикторов, как X1, X2...,Xp.
Основной компонент можно записать в виде: Z1 = 11X1 + 21X2 + 31X3 + .... + p1Xp
где:
- Z1 - является первым главным компонентом;
- p1 - является вектором нагрузки, состоящим из нагрузок (1, 2.) первого основного компонента.
Нагрузки ограничены суммой квадрата равного 1. Это связано с тем, что большая величина нагрузок может привести к большой дисперсии. Он также определяет направление основной компоненты (Z1), по которой данные больше всего различаются. Это приводит к тому, что линия в пространстве р-мер, ближе всего к n-наблюдениям.
Близость измеряется с использованием среднеквадратичного евклидова расстояния. X1..Xp являются нормированными предикторами. Нормализованные предикторы имеют среднее значение, равное нулю, а стандартное отклонение равно единице. Следовательно, первый главный компонент - это линейная комбинация исходных предикторных переменных, которая фиксирует максимальную дисперсию в наборе данных. Он определяет направление наибольшей изменчивости в данных. Чем больше изменчивость, зафиксированная в первом компоненте, тем больше информация, полученная им. Ни один другой не может иметь изменчивость выше первого основного.
Первый основной компонент приводит к строке, которая ближе всего к данным и сводит к минимуму сумму квадрата расстояния между точкой данных и линией. Второй главный компонент (Z2) также представляет собой линейную комбинацию исходных предикторов, которая фиксирует оставшуюся дисперсию в наборе данных и некоррелирована Z1. Другими словами, корреляция между первым и вторым компонентами должна равняться нулю. Он может быть представлен как: Z2 = 12X1 + 22X2 + 32X3 + .... + p2Xp.
Если они некоррелированы, их направления должны быть ортогональными.
Процесс прогнозирования тестовых данных
После того как вычислены главные компоненты начинают процесс прогнозирования тестовых данных с их использованием. Процесс метода главных компонент для чайников прост.

Например, необходимо сделать преобразование в тестовый набор, включая функцию центра и масштабирования в языке R (вер.3.4.2) и его библиотеке rvest. R - свободный язык программирования для статистических вычислений и графики. Он был реконструирован в 1992 году для решения статистических задач пользователями. Это полный процесс моделирования после извлечения PCA.
Набор данных Python:

Для реализации PCA в python импортируют данные из библиотеки sklearn. Интерпретация остается такой же, как и пользователей R. Только набор данных, используемый для Python, представляет собой очищенную версию, в которой отсутствуют вмененные недостающие значения, а категориальные переменные преобразуются в числовые. Процесс моделирования остается таким же, как описано выше для пользователей R. Метод главных компонент, пример расчета:

Спектральное разложение
Идея метода основного компонента заключается в приближении этого выражения для выполнения факторного анализа. Вместо суммирования от 1 до p теперь суммируются от 1 до m, игнорируя последние p-m членов в сумме и получая третье выражение. Можно переписать это, как показано в выражении, которое используется для определения матрицы факторных нагрузок L, что дает окончательное выражение в матричной нотации. Если используются стандартизованные измерения, заменяют S на матрицу корреляционной выборки R.

Это формирует матрицу L фактор-нагрузки в факторном анализе и сопровождается транспонированной L. Для оценки конкретных дисперсий фактор-модель для матрицы дисперсии-ковариации.
Σ = L L'+ Ψ
Теперь будет равна матрице дисперсии-ковариации минус LL ' .
Ψ = Σ - L L'
Основные компоненты определяются по формуле
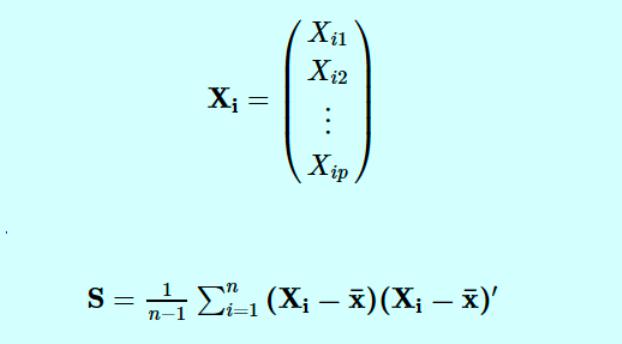
Где:
- Xi - вектор наблюдений для i-го субъекта.
- S обозначает нашу выборочную дисперсионно-ковариационную матрицу.
Тогда p собственные значения для этой матрицы ковариации дисперсии, а также соответствующих собственных векторов для этой матрицы.
Собственные значения S:λ^1, λ^2, ... , λ^п.
Собственные векторы S:е^1, e^2, ... , e^п.
Анализ Excel в биоинформатике
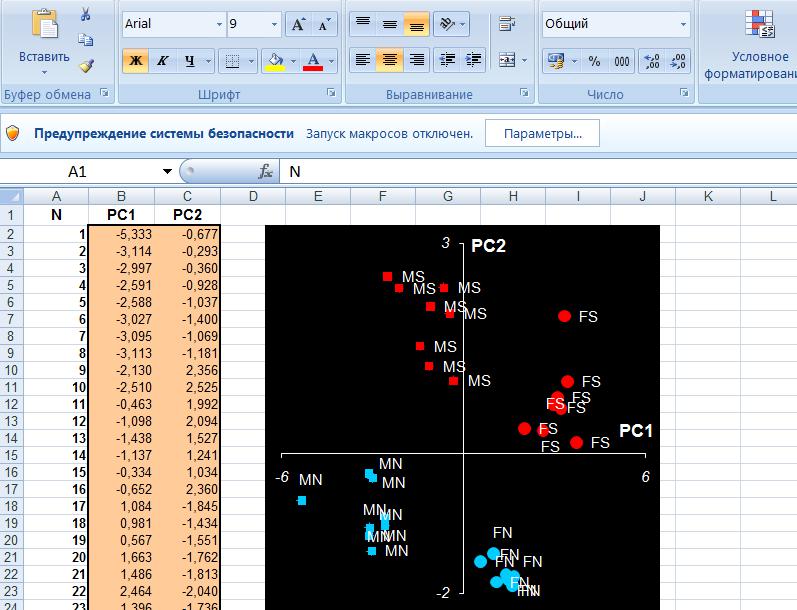
Анализ PCA - это мощный и популярный метод многомерного анализа, который позволяет исследовать многомерные наборы данных с количественными переменными. По этой методике широко используется метод главных компонент в биоинформатике, маркетинге, социологии и многих других областях. XLSTAT предоставляет полную и гибкую функцию для изучения данных непосредственно в Excel и предлагает несколько стандартных и расширенных опций, которые позволят получить глубокое представление о пользовательских данных.
Можно запустить программу на необработанных данных или на матрицах различий, добавить дополнительные переменные или наблюдения, отфильтровать переменные в соответствии с различными критериями для оптимизации чтения карт. Кроме того, можно выполнять повороты. Легко настраивать корреляционный круг, график наблюдений в качестве стандартных диаграмм Excel. Достаточно перенести данные из отчета о результатах, чтобы использовать их в анализе.
XLSTAT предлагает несколько методов обработки данных, которые будут использоваться на входных данных до вычислений основного компонента:
- Pearson, классический PCA, который автоматически стандартизирует данные для вычислений, чтобы избежать раздутого влияния переменных с большими отклонениями от результата.
- Ковариация, которая работает с нестандартными отклонениями.
- Полихорические, для порядковых данных.
Примеры анализа данных размерностей
Можно рассмотреть метод главных компонентов на примере выполнения симметричной корреляционной или ковариационной матрицы. Это означает, что матрица должна быть числовой и иметь стандартизованные данные. Допустим, есть набор данных размерностью 300 (n) × 50 (p). Где n - представляет количество наблюдений, а p - число предикторов.
Поскольку имеется большой p = 50, может быть p(p-1)/2 диаграмма рассеяния. В этом случае было бы хорошим подходом выбрать подмножество предиктора p (p<< 50), который фиксирует количество информации. Затем следует составление графика наблюдения в полученном низкоразмерном пространстве. Не следует забывать, что каждое измерение является линейной комбинацией р-функций.
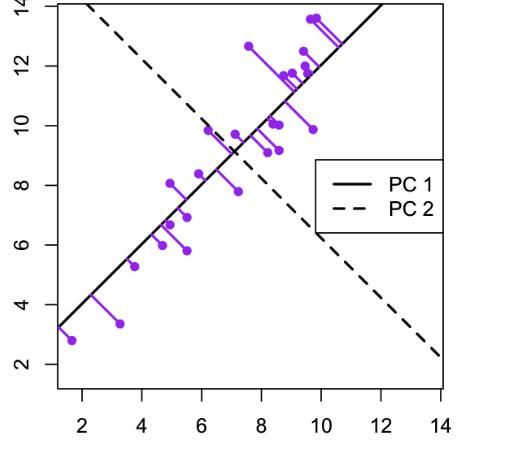
Пример для матрицы с двумя переменными. В этом примере метода главных компонентов создается набор данных с двумя переменными (большая длина и диагональная длина) с использованием искусственных данных Дэвиса.
Компоненты можно нарисовать на диаграмме рассеяния следующим образом.
Этот график иллюстрирует идею первого или главного компонента, обеспечивающего оптимальную сводку данных - никакая другая линия, нарисованная на таком графике рассеяния, не создаст набор прогнозируемых значений точек данных на линии с меньшей дисперсией.
Первый компонент также имеет приложение в регрессии с уменьшенной главной осью (RMA), в которой предполагается, что как x-, так и y-переменные имеют ошибки или неопределенности или, где нет четкого различия между предсказателем и ответом.
Эконометрические модели прогнозирования
Метод главных компонентов в эконометрике - это анализ переменных, таких как ВНП, инфляция, обменные курсы и т. д. Их уравнения затем оцениваются по имеющимся данным, главным образом совокупным временным рядам. Однако эконометрические модели могут использоваться для многих приложений, а не для макроэкономических. Таким образом, эконометрика означает экономическое измерение.
Применение статистических методов к соответствующей эконометрике данных показывает взаимосвязь между экономическими переменными. Простой пример эконометрической модели. Предполагается, что ежемесячные расходы потребителей линейно зависят от доходов потребителей в предыдущем месяце. Тогда модель будет состоять из уравнения

Задачей эконометрика является получение оценок параметров a и b. Эти оценочные значения параметров, если они используются в уравнении модели, позволяют прогнозировать будущие значения потребления, которые будут зависеть от дохода предыдущего месяца. При разработке этих видов моделей необходимо учитывать несколько моментов:
- характер вероятностного процесса, который генерирует данные;
- уровень знаний об этом;
- размер системы;
- форма анализа;
- горизонт прогноза;
- математическая сложность системы.
Все эти предпосылки важны, потому что от них зависят источники ошибок, вытекающих из модели. Кроме того, для решения этих проблем необходимо определить метод прогнозирования. Его можно привести к линейной модели, даже если имеется только небольшая выборка. Этот тип является одним из самых общих, для которого можно создать прогнозный анализ.
Непараметрическая статистика
Метод главных компонент для непараметрических данных относится к методам измерения, в которых данные извлекаются из определенного распределения. Непараметрические статистические методы широко используются в различных типах исследований. На практике, когда предположение о нормальности измерений не выполняется, параметрические статистические методы могут приводить к вводящим в заблуждение результатам. Напротив, непараметрические методы делают гораздо менее строгие предположения о распределении по измерениям.
Они являются достоверными независимо от лежащих в их основе распределений наблюдений. Из-за этого привлекательного преимущества для анализа различных типов экспериментальных конструкций было разработано много разных типов непараметрических тестов. Такие проекты охватывают дизайн с одной выборкой, дизайн с двумя образцами, дизайн рандомизированных блоков. В настоящее время непараметрический байесовский подход с применением метода главных компонентов используется для упрощения анализа надежности железнодорожных систем.
Железнодорожная система представляет собой типичную крупномасштабную сложную систему с взаимосвязанными подсистемами, которые содержат многочисленные компоненты. Надежность системы сохраняется за счет соответствующих мер по техническому обслуживанию, а экономичное управление активами требует точной оценки надежности на самом низком уровне. Однако данные реальной надежности на уровне компонентов железнодорожной системы не всегда доступны на практике, не говоря уже о завершении. Распределение жизненных циклов компонентов от производителей часто скрывается и усложняется фактическим использованием и рабочей средой. Таким образом, анализ надежности требует подходящей методологии для оценки времени жизни компонента в условиях отсутствия данных об отказах.
Метод главных компонент в общественных науках используется для выполнения двух главных задач:
- анализа по данным социологических исследований;
- построения моделей общественных явлений.
Алгоритмы расчета моделей
Алгоритмы метода главных компонент дают другое представление о структуре модели и ее интерпретации. Они являются отражением того, как PCA используется в разных дисциплинах. Алгоритм нелинейного итеративного частичного наименьшего квадрата NIPALS представляет собой последовательный метод вычисления компонентов. Вычисление может быть прекращено досрочно, когда пользователь считает, что их достаточно. Большинство компьютерных пакетов имеют тенденцию использовать алгоритм NIPALS, поскольку он имеет два основных преимущества:
- он обрабатывает отсутствующие данные;
- последовательно вычисляет компоненты.
Цель рассмотрения этого алгоритма:
- дает дополнительное представление о том, что означают нагрузки и оценки;
- показывает, как каждый компонент не зависит ортогонально от других компонентов;
- показывает, как алгоритм может обрабатывать недостающие данные.
Алгоритм последовательно извлекает каждый компонент, начиная с первого направления наибольшей дисперсии, а затем второго и т. д. NIPALS вычисляет один компонент за раз. Вычисленный первый эквивалентен t1t1, а также p1p1 векторов, которые были бы найдены из собственного значения или разложения по сингулярным значениям, может обрабатывать недостающие данные в XX. Он всегда сходится, но сходимость иногда может быть медленной. И также известен, как алгоритм мощности для вычисления собственных векторов и собственных значений и отлично работает для очень больших наборов данных. Google использовал этот алгоритм для ранних версий своей поисковой системы.
Алгоритм NIPALS показан на фото ниже.

Оценки коэффициента матрицы Т затем вычисляется как T=XW и в частичной мере коэффициентов регрессии квадратов B из Y на X, вычисляются, как B = WQ. Альтернативный метод оценки для частей регрессии частичных наименьших квадратов можно описать следующим образом.

Метод главных компонентов - это инструмент для определения основных осей дисперсии в наборе данных и позволяет легко исследовать ключевые переменные данных. Правильно примененный метод является одним из самых мощных в наборе инструментов анализа данных.











