Сортировка слиянием - это один из базовых алгоритмов информатики, сформулированный еще в 1945 году великим математиком Джоном фон Нейманом. Участвуя в «Манхеттенском проекте», Нейман столкнулся с необходимостью эффективной обработки огромных массивов данных. Разработанный им метод использовал принцип «разделяй и властвуй», что позволило существенно сократить время, необходимое для работы.
Принцип и использование алгоритма
Метод сортировки слиянием находит применение в задачах сортировки структур, имеющих упорядоченный доступ к элементам, например, массивов, списков, потоков.
При обработке исходный блок данных дробится на маленькие составляющие, вплоть до одного элемента, который по сути уже является отсортированным списком. Затем происходит обратная сборка в правильном порядке.
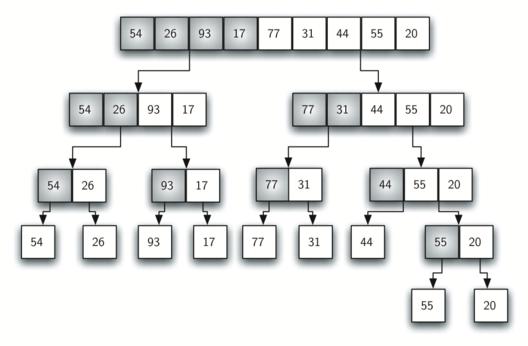
Для сортировки массива определенной длины требуется дополнительная область памяти аналогичного размера, в которой по частям собирается отсортированный массив.
Метод может использоваться для упорядочивания любых сравнимых типов данных, например, чисел или строк.
Слияние отсортированных участков
Для понимания алгоритма начнем его разбор с конца - с механизма слияния отсортированных блоков.
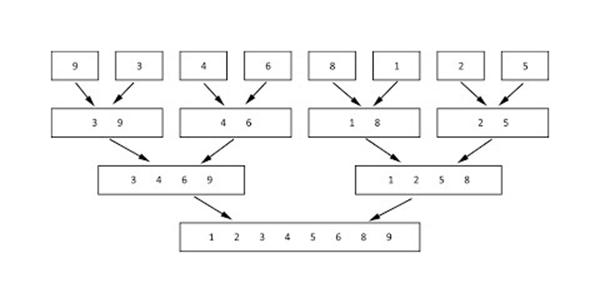
Представим, что у нас есть два любым способом отсортированных массива чисел, которые необходимо объединить друг с другом так, чтобы сортировка не нарушилась. Для простоты будем упорядочивать числа по возрастанию.
Элементарный пример: оба массива состоят из одного элемента каждый.
int[] arr1 = {31};
int[] arr2 = {18};Чтобы слить их, нужно взять нулевой элемент первого массива (не забудьте, что нумерация начинается с нуля) и нулевой элемент второго массива. Это, соответственно, 31 и 18. По условию сортировки число 18 должно идти первым, так как оно меньше. Просто расставляем числа в правильном порядке:
int[] result = {18, 31};Обратимся к примеру посложнее, в котором каждый массив состоит из нескольких элементов:
int[] arr1 = {2, 17, 19, 45};
int[] arr2 = {5, 6, 21, 30};Алгоритм слияния будет заключаться в последовательном сравнивании меньших элементов и размещении их в результирующем массиве в правильном порядке. Для отслеживания текущих индексов введем две переменные - index1 и index2. Изначально приравняем их к нулю, так как массивы отсортированы, и самые меньшие элементы стоят в начале.
int index1 = 0;
int index2 = 0;Распишем по шагам весь процесс слияния:
- Берем из массива arr1 элемент с индексом index1, а из массива arr2 - с индексом index2.
- Сравниваем, отбираем наименьший из них и помещаем в результирующий массив.
- Увеличиваем текущий индекс меньшего элемента на 1.
- Продолжаем с первого шага.
На первом витке ситуация будет выглядеть так:
index1 = 0;
index2 = 0;
arr1[0] = 2;
arr2[0] = 5;
arr1[0] < arr2[0];
index1++;
result[0] = arr1[0]; // result = [2]На втором витке:
index1 = 1;
index2 = 0;
arr1[1] = 17;
arr2[0] = 5;
arr1[1] > arr2[0];
index2++;
result[1] = arr2[0]; // result = [2, 5]На третьем:
index1 = 1;
index2 = 1;
arr1[1] = 17;
arr2[1] = 6;
arr1[1] > arr2[1];
index2++;
result[2] = arr2[1]; // result = [2, 5, 6]И так далее, пока в итоге не получится полностью отсортированный результирующий массив: {2, 5, 6, 17, 21, 19, 30, 45}.
Определенные сложности могут возникнуть, если сливаются массивы с разными длинами. Что делать, если один из текущих индексов достиг последнего элемента, а во втором массиве еще остаются члены?
int[] arr1 = {1, 4};
int[] arr2 = {2, 5, 6, 7, 9};
// 1 step
index1 = 0, index2 = 0;
1 < 2
result = {1};
// 2 step
index1 = 1, index2 = 0;
4 > 2
result = {1, 2};
// 3 step
index1 = 1, index2 = 1;
4 < 5
result = {1, 2, 4};
//4 step
index1 = 2, index2 = 1
??Переменная index1 достигла значения 2, однако массив arr1 не имеет элемента с таким индексом. Здесь все просто: достаточно перенести оставшиеся элементы второго массива в результирующий, сохранив их порядок.
result = {1, 2, 4, 5, 6, 7, 9};Эта ситуация указывает нам на необходимость сопоставлять текущий индекс проверки с длиной сливаемого массива.
Схема слияния упорядоченных последовательностей (A и B) разной длины:
- Если длина обеих последовательностей больше 0, сравнить A[0] и B[0] и переместить меньший из них в буфер.
- Если длина одной из последовательностей равна 0, взять оставшиеся элементы второй последовательности и, не меняя их порядок, перенести в конец буфера.
Реализация второго этапа
Пример объединения двух отсортированных массивов на языке Java приведен ниже.
int[] a1 = new int[] {21, 23, 24, 40, 75, 76, 78, 77, 900, 2100, 2200, 2300, 2400, 2500};
int[] a2 = new int[] {10, 11, 41, 50, 65, 86, 98, 101, 190, 1100, 1200, 3000, 5000};
int[] a3 = new int[a1.length + a2.length];
int i=0, j=0;
for (int k=0; k<a3.length; k++) {
if (i > a1.length-1) {
int a = a2[j];
a3[k] = a;
j++;
}
else if (j > a2.length-1) {
int a = a1[i];
a3[k] = a;
i++;
}
else if (a1[i] < a2[j]) {
int a = a1[i];
a3[k] = a;
i++;
}
else {
int b = a2[j];
a3[k] = b;
j++;
}
}Здесь:
- a1 и a2 – исходные отсортированные массивы, которые необходимо объединить;
- a3 – конечный массив;
- i и j – индексы текущих элементов для массивов a1 и a2.
Первое и второе условие if обеспечивает то, что индексы не выйдут за пределы размера массива. Третий и четвертый блоки условий, соответственно, перемещают в результирующий массив меньшего элемента.

Разделяй и властвуй
Итак, мы научились объединять отсортированные коллекции значений. Можно сказать, вторая часть алгоритма сортировки слиянием - непосредственно слияние - уже разобрана.
Однако необходимо еще понять, как от исходного несортированного массива чисел добраться до нескольких отсортированных, которые можно будет слить.
Рассмотрим первую стадию алгоритма и научимся разделять массивы.
В этом нет ничего сложного - исходный список значений делится пополам, затем каждая часть также раздваивается, и так до тех пор, пока не получатся совсем маленькие блоки.
Длина таких минимальных элементов может быть равна единице, то есть они могут сами по себе являться отсортированным массивом, однако это не обязательное условие. Размер блока определяется заранее, а для его упорядочивания может использоваться любой подходящий алгоритм сортировки, эффективно работающий с массивами малых размеров (например, быстрая сортировка или сортировка вставками).
Выглядит это следующим образом.
// исходный массив
{34, 95, 10, 2, 102, 70};
// первое разделение
{34, 95, 10} и {2, 102, 70};
// второе разделение
{34} и {95, 10} и {2} и {102, 70}Полученные блоки, состоящие из 1-2 элементов, очень просто упорядочить.
После этого необходимо объединить уже отсортированные маленькие массивы попарно, сохранив порядок членов, что мы уже научились делать.
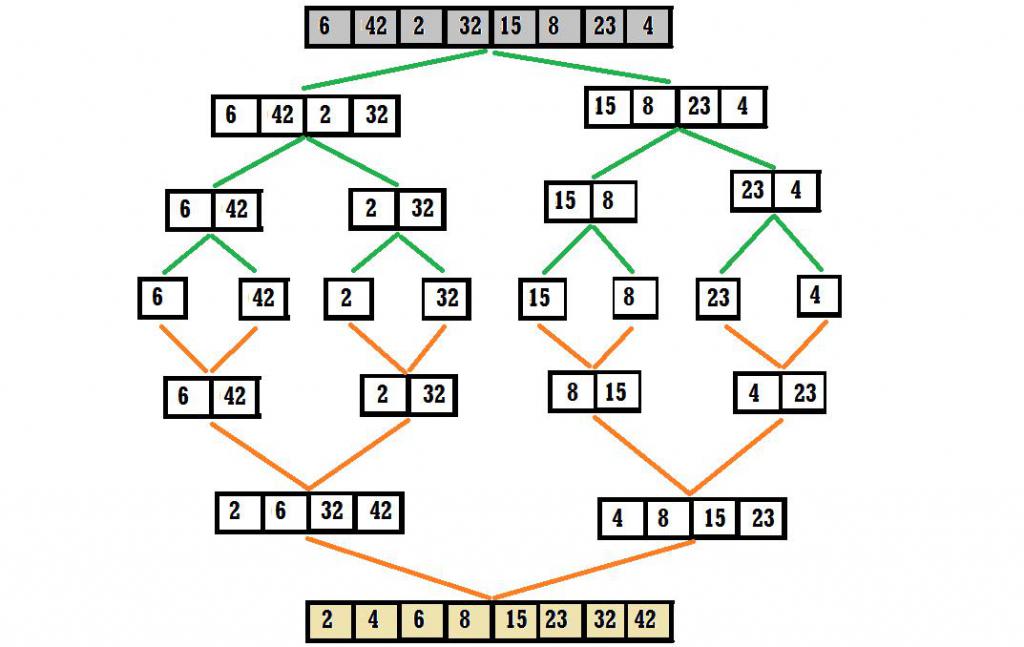
Реализация первого этапа
Рекурсивное разбиение массива показано ниже.
void mergeSort(T a[], long start, long finish) {
long split;
if (start < finish) {
split = (start + finish)/2;
mergeSort(a, start, split);
mergeSort(a, split+1, finish);
merge(a, start, split, finish);
}
}Что происходит в этом коде:
- Функция mergeSort получает исходный массив
aи левую и правую границы участка, который необходимо отсортировать (индексы start иfinish). - Если длина этого участка больше единицы (
start < finish), то он разбивается на две части (по индексуsplit), и каждая из них рекурсивно сортируется. - В рекурсивный вызов функции для левой стороны передается начальный индекс участка и индекс
split. Для правой, соответственно, началом будет(split + 1), а концом - последний индекс исходного участка. - Функция
mergeполучает две упорядоченных последовательности (a[start]...a[split]иa[split+1]...a[finish]) и сливает их с сохранением порядка сортировки.
Механика работы функции merge рассмотрена выше.
Общая схема алгоритма
Метод сортировки массива слиянием состоит из двух больших этапов:
- Разделить неотсортированный исходный массив на маленькие части.
- Собрать их попарно, соблюдая правило сортировки.
Большая и сложная задача здесь разбивается на много простых, которые последовательно решаются, приводя к желаемому результату.
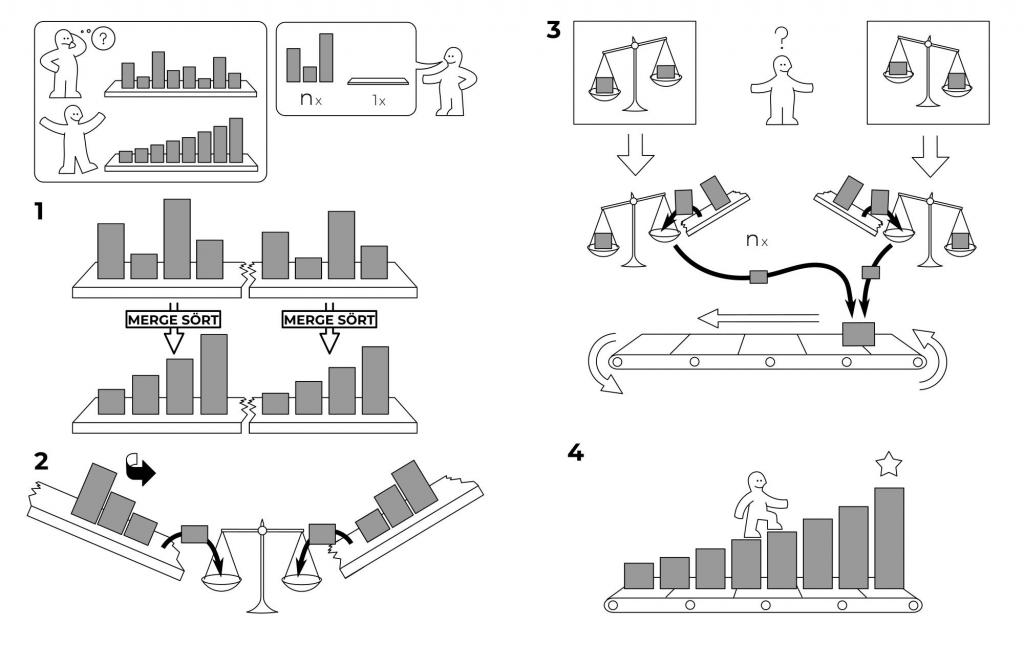
Оценка работы метода
Временная сложность сортировки слиянием определяется высотой дерева разбиений алгоритма и равна количеству элементов в массиве (n), умноженному на его логарифм (log n). Такая оценка называется логарифмической.
Это одновременно и достоинство, и недостаток метода. Время его работы не меняется даже в худшем случае, когда исходный массив отсортирован в обратном порядке. Однако при обработке полностью отсортированных данных алгоритм не обеспечивает выигрыша во времени.
Важно отметить и затраты памяти при работе метода сортировки слиянием. Они равны размеру исходной коллекции. В этой дополнительно выделенной области из кусочков собирается отсортированный массив.
Реализация алгоритма
Сортировка слиянием в Паскале показана ниже.
Procedure MergeSort(name: string; var f: text);
Var a1,a2,s,i,j,kol,tmp: integer;
f1,f2: text;
b: boolean;
Begin
kol:=0;
Assign(f,name);
Reset(f);
While not EOF(f) do
begin
read(f,a1);
inc(kol);
End;
Close(f);
Assign(f1,'{имя 1-го вспомогательного файла}');
Assign(f2,'{имя 2-го вспомогательного файла}');
s:=1;
While (s<kol) do
begin
Reset(f); Rewrite(f1); Rewrite(f2);
For i:=1 to kol div 2 do
begin
Read(f,a1);
Write(f1,a1,' ');
End;
If (kol div 2) mod s<>0 then
begin
tmp:=kol div 2;
While tmp mod s<>0 do
begin
Read(f,a1);
Write(f1,a1,' ');
inc(tmp);
End;
End;
While not EOF(f) do
begin
Read(f,a2);
Write(f2,a2,' ');
End;
Close(f); Close(f1); Close(f2);
Rewrite(f); Reset(f1); Reset(f2);
Read(f1,a1);
Read(f2,a2);
While (not EOF(f1)) and (not EOF(f2)) do
begin
i:=0; j:=0;
b:=true;
While (b) and (not EOF(f1)) and (not EOF(f2)) do
begin
If (a1<a2) then
begin
Write(f,a1,' ');
Read(f1,a1);
inc(i);
End
else
begin
Write(f,a2,' ');
Read(f2,a2);
inc(j);
End;
If (i=s) or (j=s) then b:=false;
End;
If not b then
begin
While (i<s) and (not EOF(f1)) do
begin
Write(f,a1,' ');
Read(f1,a1);
inc(i);
End;
While (j<s) and (not EOF(f2)) do
begin
Write(f,a2,' ');
Read(f2,a2);
inc(j);
End;
End;
End;
While not EOF(f1) do
begin
tmp:=a1;
Read(f1,a1);
If not EOF(f1) then
Write(f,tmp,' ')
else
Write(f,tmp);
End;
While not EOF(f2) do
begin
tmp:=a2;
Read(f2,a2);
If not EOF(f2) then
Write(f,tmp,' ')
else
Write(f,tmp);
End;
Close(f); Close(f1); Close(f2);
s:=s*2;
End;
Erase(f1);
Erase(f2);
End;Визуально работа алгоритма выглядит так (сверху - неупорядоченная последовательность, снизу - упорядоченная).
Внешняя сортировка данных
Очень часто появляется необходимость отсортировать некоторые данные, расположенные во внешней памяти ЭВМ. В ряде случаев они имеют внушительные размеры и не могут быть размещены в оперативной памяти для облегчения доступа к ним. Для таких случаев используются методы внешних сортировок.
Необходимость обращаться к внешним носителям ухудшает временную эффективность обработки.
Сложность работы состоит в том, что алгоритм в каждый момент времени может иметь доступ только к одному элементу потока данных. И в этом случае один из лучших результатов показывает именно метод сортировки слиянием, который может сравнивать элементы двух файлов последовательно один за другим.
Чтение данных из внешнего источника, их обработка и запись в конечный файл осуществляются упорядоченными блоками (сериями). По способу работы с размером упорядоченных серий выделяют два вида сортировки: простое и естественное слияние.
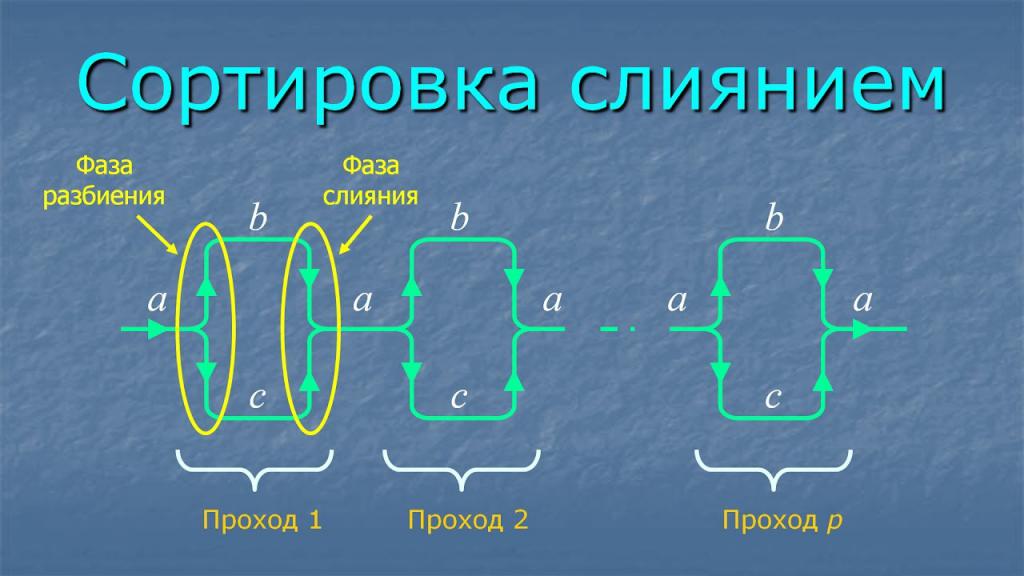
Простое слияние
При простом слиянии длина серии фиксируется.
Так, в исходном несортированном файле все серии состоят из одного элемента. После первого шага размер увеличивается до двух. Далее - 4, 8, 16 и так далее.
Работает это следующим образом:
- Исходный файл (f) делится на два вспомогательных - f1, f2.
- Они вновь сливаются в один файл (f), но при этом все элементы попарно сравниваются и образуют уже пары. Размер серии на этом шаге становится равен двум.
- Повторяется шаг 1.
- Повторяется шаг 2, но при этом сливаются уже упорядоченные двойки, образуя отсортированные четверки.
- Цикл продолжается, сопровождаясь увеличением серии на каждом витке, до тех пор, пока весь файл не будет отсортирован.
Как понять, что внешняя сортировка простым слиянием завершена?
- новая длина серии (после слияния) не менее общего количества элементов;
- осталась всего одна серия;
- вспомогательный файл f2 остался пуст.
Недостатки простого слияния следующие: так как длина серий фиксирована на каждом проходе слияния, частично упорядоченные данные будут обрабатываться так же долго, как и абсолютно хаотичные.
Естественное слияние
Этот метод не ограничивает длину серий, а выбирает максимально возможные.
Алгоритм сортировки:
- Начинается считывание исходной последовательности из файла f. Первый полученный элемент записывается в файл f1.
- Если следующая запись удовлетворяет условию сортировки, она записывается туда же, если нет - то во второй вспомогательный файл f2.
- Таким образом распределяются все записи исходного файла, а в f1 образуется упорядоченная последовательность, которая и определяет текущий размер серии.
- Файлы f1 и f2 сливаются.
- Цикл повторяется.
Из-за нефиксированного размера серии приходится обозначать окончание последовательности специальным символом. Поэтому при слиянии увеличивается количество сравнений. Кроме того, размер одного из вспомогательных файлов может приближаться к размеру исходного.
В среднем метод естественного слияния работает эффективнее по сравнению с простым слиянием при внешней сортировке.
Особенности алгоритма
При сравнении двух одинаковых значений метод сохраняет их исходный порядок, то есть является устойчивым.
Процесс сортировки может быть весьма успешно разделен на несколько потоков.
На видео наглядно продемонстрирована работа алгоритма сортировки массива слиянием.