


NoSQL представляют собой хранилище, которое не соответствует модели реляционных баз данных и их характеристикам, у них нет схем, они не объединяются, и не гарантируют свойство ACID. Масштабируется NO-система горизонтально и использует широкий объем основной памяти компьютера, решая проблему больших объемов информации.
Собственные проприетарные типы – это новая методология разработки нереляционных баз данных NoSQL, выполненная крупными компаниями для удовлетворения корпоративных нужд, такими, например, как BigTable от Google, который считается первой системой NoSQL, и Amazon DynamoDB. Успех этих систем положил начало разработке ряда похожих систем БД с открытым исходным кодом и проприетарных БД, наиболее популярными из которых являются Hypertable, Cassandra, MongoDB, DynamoDB,
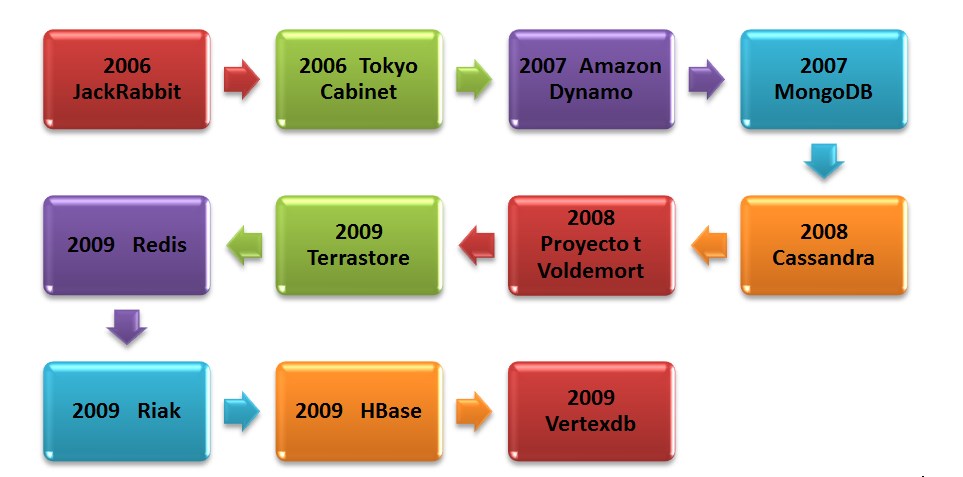
Эволюция NoSQL
Проблема масштабируемости SQL была признана компаниями Web 2.0 с огромными, растущими потребностями в данных и инфраструктуре, такими как Google, Amazon и Facebook. Они нашли собственные решения проблем, внедрив технологии BigTable, DynamoDB и Cassandra. Растущий интерес привел к появлению ряда систем управления базами данных NoSQL (СУБД) с акцентом на производительность, надежность и согласованность. Ряд существующих структур индексации были повторно использованы и улучшены с целью повышения производительности поиска и чтения.
Термин был придуман Калором Строцци еще в 1998 году, а воскрешен в 2009 году сотрудником Rackspace Эриком Эвансом для решения проблем веб-компаний с большим объемом операций и информации.
Одно ключевое отличие между базами данных NoSQL и традиционными реляционными БД заключается в том, что первая является формой неструктурированного хранилища.
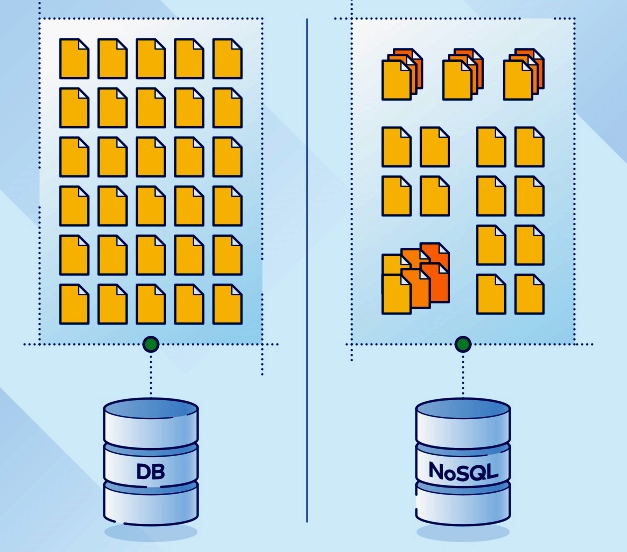
Таким образом NoSQL не имеют фиксированной структуры таблиц, как в реляционной системе. В этой таблице приведено краткое сравнение возможностей NoSQL и SQL.
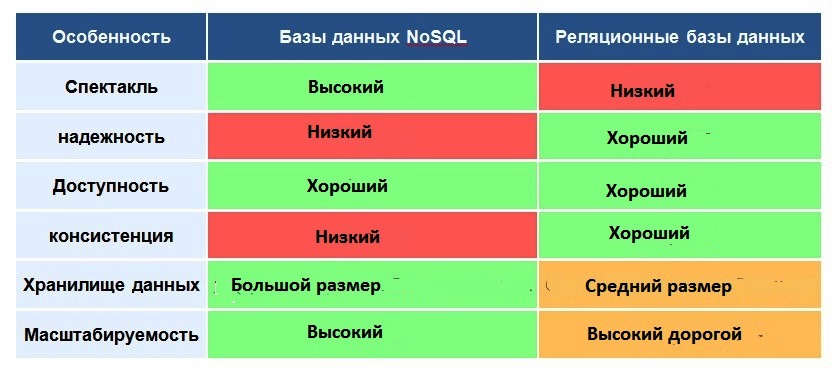
Следует отметить, что таблица показывает сравнение на уровне базы данных, а не СУБД, которые реализуют обе модели. Эти системы предоставляют собственные запатентованные методы для преодоления некоторых проблем и недостатков обеих систем, что значительно повышает производительность и надежность.
Типы информационных хранилищ
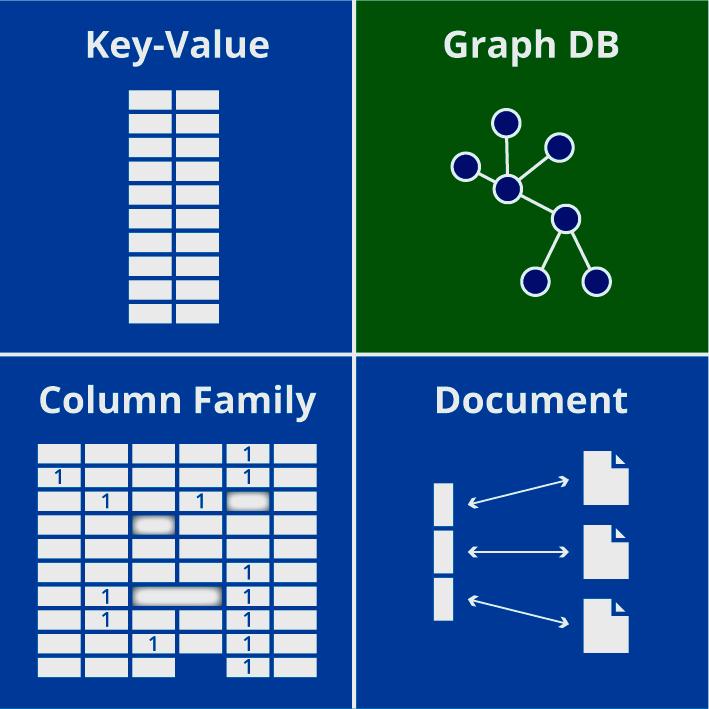
В типе баз данных NoSQL Key-Value используется хеш-таблица, в которой уникальный ключ указывает на элемент. Они могут быть организованы в логические группы, требуя в своих пределах уникальности. Это позволяет использовать идентичные ключи в разных логических группах. Некоторые реализации БД предоставляют механизмы кэширования, которые значительно повышают их производительность.
Все, что нужно для работы с предметами, хранящимися в базе данных - это ключ. Данные хранятся в виде строки JSON или BLOB (большой двоичный объект). Одним из самых больших недостатков этой формы является отсутствие согласованности на уровне БД. Это может быть добавлено во время разработки базы данных NoSQL программистами со своим собственным кодом, но это также требует больше усилий, из-за сложности реализации и времени. Самая известная БД NoSQL, построенная на хранилище значений ключей - это Amazon DynamoDB.
Хранилища документов (Document) аналогичны хранилищам значений ключей в том, что они не содержат схемы и основаны на модели значений. Следовательно, оба типа имеют одинаковые преимущества и недостатки. И той, и другой не хватает согласованности на уровне базы данных, что не позволяет приложениям предоставлять больше надежных функций. Тем не менее существуют некоторые ключевое различие между ними. В хранилищах документов значения (документы) обеспечивают кодировку для хранимых данных. Такими кодировками могут быть XML, JSON или BSON (двоичный код JSON). Самым популярным приложением БД, использующим хранилище документов, является MongoDB.
В базе данных Column Family данные хранятся в столбцах, а не в строках, как это делается в большинстве систем управления реляционными БД. Хранилище столбцов состоит из одного или нескольких семейств столбцов, которые логически группируют определенные столбцы в БД. Ключ используется для идентификации и указания количества столбцов с атрибутом пространства ключей, который определяет область его действия. Каждый столбец содержит кортежи имен и значений, упорядоченные и разделенные запятыми.
Хранилища столбцов имеют быстрый доступ для чтения/записи к сохраненным данным. В нем столбцы строки соответствую одному столбцу и хранятся, как одна запись на диске. Это обеспечивает более быстрый доступ во время операций чтения/записи. Наиболее популярные базы данных, которые используют хранилище столбцов баз данных NoSQL, примеры: Google BigTable, HBase и Cassandra.
В БД NoSQL Graph Bd для представления данных используется структура ориентированного графа. Граф состоит из ребер и узлов.
Принцип работы БД

NoSQL работают, как файл, в котором хранятся все данные, они позволяют работать с огромным количеством информации и организовывают ее так, чтобы пользователи могли обращаться к ней в любое время, когда это будет нужно. В настоящее время существуют разные типы NoSQL, каждый из них работает по-разному, большинство написано на C ++. Можно сказать, что БД NoSQL центрируют свои функции на основе:
- Горизонтальной масштабируемости с возможностью увеличения своего размера, увеличения пространства хранения в БД без ущерба для работы.
- Облачной технологии. Большинство БД NoSQL базируют свое хранилище в облаке, чтобы освободить больше места. Кроме того, у них есть узлы для репликации информации.
- Эффективного использования ресурсов. Компании в настоящее время находятся в процессе технологического перехода, поэтому практически необходимо, чтобы у них была БД, позволяющая им внедрять новые технологические инструменты. Данные NoSQL работают именно для этого - гибкая модель позволяет быстро адаптироваться к новым инструментам.
- Свободной схемы функционирования. NoSQL не имеют жесткой системы, поэтому у программистов есть свобода изменять данные по необходимости. Это означает, что если требуется изменить определение поля или типа данных, то в этом нет проблем в отличие от баз SQL, где изменения подобного рода связаны с большими сложностями.
- Скоростью отклика. Скорость в БД измеряется задержкой, которая является временем отклика, NoSQL озабочены максимально возможным уменьшением времени задержки.
- Использование индексов. SQL и NoSQL нуждаются в индексах, поскольку запросы не могут быть сделаны в миллионах записей, если индекс не был настроен. В NoSQL индексы генерируются в форме B-Tree, то есть узлы сбалансированы, а значит увеличивается скорость поиска.
Системы управления
В следующей таблице приведено краткое сравнение между различными системами управления БД NoSQL.
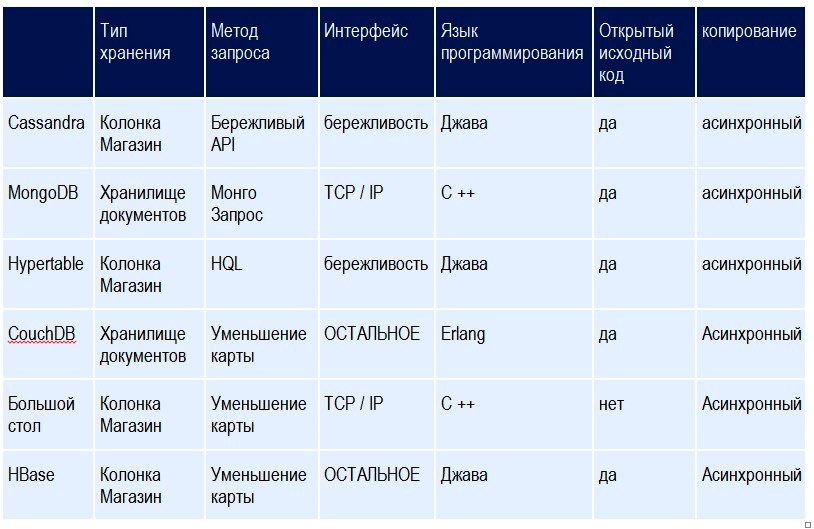
MongoDB имеет гибкое хранилище схем - это означает, что хранимые объекты не обязательно должны иметь одинаковую структуру или поля. Он также имеет некоторые функции оптимизации, которые распределяют коллекции данных между собой, что приводит к общему улучшению производительности и более сбалансированной системе. Другие системы NoSQL, такие, как Apache CouchDB, также являются БД типа хранилища документов и имеют много общих возможностей с MongoDB, за исключением того, что к БД можно получить доступ с помощью API RESTful.
REST - это архитектурный стиль, состоящий из скоординированного набора архитектурных ограничений, применяемых к компонентам, соединителям и элементам данных в интернете. Он основан на кешируемом коммуникационном протоколе "клиент - сервер" без сохранения состояния, например, HTTP-протокол. Приложения RESTful используют HTTP-запросы для публикации, чтения и удаления данных. Что касается баз данных столбцов, Hypertable - это БД NoSQL, написанная на C ++ и основанная на Google BigTable. Hypertable поддерживает распределение хранилищ данных по узлам для обеспечения максимальной масштабируемости, как MongoDB и CouchDB.
Гибридная система Cassandra

Одна из наиболее широко используемых БД NoSQL - Cassandra, разработанная Facebook. Целью Cassandra было создание СУБД, которая не имеет единой точки отказа и обеспечивает максимальную доступность. Cassandra - это, главным образом, БД хранилища столбцов. В некоторых исследованиях она упоминалась как гибридная система, основанная на Google BigTable, которой является БД хранилища столбцов и Amazon DynamoDB, присущая типу «ключ-значение». Ключи в Cassandra указывают на набор семейств столбцов с опорой на распределенную файловую систему Google BigTable и функции доступности Dynamo (распределенная хеш-таблица).
Основные характеристики Cassandra включают в себя:
- Отсутствие единой точки отказа. Для этого она должна работать на кластере узлов, а не на одной машине. Это не означает, что данные на каждом кластере одинаковы. Когда происходит сбой в одном из узлов, данные на нем будут недоступны. Однако другие узлы и данные по-прежнему будут доступны.
- Распределенное хеширование - это схема, которая обеспечивает функциональность хэш-таблицы таким образом, что добавление или удаление одного слота не приводит к значительному изменению отображения ключей на слоты. Это позволяет распределять нагрузку на серверы или узлы в соответствии с их емкостью и минимизировать время простоя.
- Относительно простой в использовании клиентский интерфейс. Она использует Apache Thrift для своего клиентского интерфейса, который предоставляет RPC-клиент на нескольких языках, но большинство разработчиков предпочитают альтернативы с открытым исходным кодом, созданные на основе Apple Thrift, например, Hector.
- Репликация данных. По сути, он отражает данные для других узлов в кластере. Репликация может быть случайной или определенной для максимальной защиты данных, например, путем размещения в узле другого центра обработки данных.
- Политика разделения решает, где и на каком узле разместить ключ. Это может быть случайным или упорядоченным процессом. При использовании обоих типов политик разделения Cassandra может найти баланс между нагрузкой и оптимизацией производительности запросов.
- Согласованность. Репликация усложняет согласованность. Это связано с тем, что все узлы должны быть обновлены в любой момент времени с самыми последними значениями или во время запуска операции чтения.
- Чтение/запись действий. Клиент отправляет запрос одному узлу. Узел, согласно политики репликации, сохраняет данные в кластере. Каждый узел сначала изменяет данные в журнале фиксации и обновляет структуру таблицы, причем оба изменения выполняются синхронно. Запрос на чтение отправляется одному единственному узлу, который содержит данные в соответствии с политикой разделения/размещения.
Структуры индексации

Индексирование - это процесс связывания ключа с расположением соответствующей записи данных в СУБД. Существует множество структур индексирования данных, используемых в базах данных NoSQL. B-Tree является одной из наиболее распространенных структур индекса в СУБД. В ней внутренние узлы могут иметь переменное количество дочерних узлов в предопределенном диапазоне.
Одно из основных отличий от других древовидных структур, таких как AVL, заключается в том, что B-Tree позволяет иметь переменное количество дочерних узлов, что означает меньшую балансировку дерева, но большую потерю пространства. B + Tree - один из самых популярных вариантов B-деревьев. Это улучшение (в отличие от B-Tree) требует, чтобы все ключи находились в листьях.
Структура данных T-Trees была разработана путем объединения функций AVL-Trees и B-Trees. Деревья AVL относятся к типу самобалансирующихся деревьев двоичного поиска, тогда как деревья B - несбалансированы, а у каждого узла может быть разное количество дочерних элементов.
В T-дереве структура очень похожа на AVL-дерево и B-дерево. Каждый узел хранит более одного кортежа {key-value, pointer}. Кроме того, двоичный поиск используется в сочетании с узлами и несколькими кортежами, чтобы обеспечить лучшую память и производительность.
T-дерево имеет три типа узлов: с правым и левым дочерним узлом, конечный узел без дочерних узлов и узел с половинным листом только с одним дочерним узлом. Считается, что у T-Trees лучшая общая производительность.
Распространенные ошибки применения БД
Существуют три распространенные ошибки, которые совершают организации, когда дело доходит до NoSQL:
- NoSQL - это больше, чем масштабируемость, нельзя приравнивать NoSQL к веб-шкале. Прародителями современных нереляционных баз данных были такие компании, как Google и Amazon, которые сосредоточились на том, чтобы решать проблемы масштабируемости в веб-среде.
- Разработчики должны развиваться. В одном высококлассном веб-проекте плохо отобранная команда по интеграции создала огромную проблему, и чтобы устранить ее, потребовались время и миллионы долларов.
- Усложненное распространение. Ничто не заменит знания и опыт ни в реализации, ни в процессе администрирования. Случается так, что запрос, который быстро выполняется на локальной машине разработки, не будет масштабироваться горизонтально на сотнях машин. Современное приложение имеет распределенную архитектуру и множество пользователей одновременно, которые требуют быстрых ответов.
Преимущества NoSQL
Базы данных NoSQL и SQL конкурируют между собой, но, по мнению многих специалистов, первая имеет больше преимуществ по сравнению с традиционными реляционными базами данных:
- Имеют простую и гибкую структуру.
- Не имеет схем.
- Основана на парах "ключ-значение".
- Некоторые типы включают хранилище столбцов, документов, значений ключей, графиков, объектов, XML и другие режимы данных.
- Обычно каждое значение в БД имеет ключ. Некоторые хранилища позволяют разработчикам хранить сериализованные объекты, а не только простые строковые значения.
- NoSQL с открытым исходным кодом не требуют дорогостоящих лицензионных сборов и могут работать на недорогом оборудовании, что делает их развертывание рентабельным.
- При работе с NoSQL, независимо от того, являются ли они открытыми или проприетарными, расширение проще и дешевле, чем при работе с реляционными базами данных. Оно выполняется путем горизонтального масштабирования и распределения нагрузки по всем узлам, а не по типу вертикального масштабирования, который обычно выполняется в системах реляционных баз данных и заменяет основной хост более мощным.
Недостатки No-системы
Базы данных NoSQL работают по-разному, все зависит от документов, которые в них хранятся, но можно сказать, что они являются важным инструментом в современных компаниях, поскольку хранят необходимую информацию пользователей и операций.
Они не идеальны, поэтому не всегда являются правильным выбором для программистов. С одной стороны, большинство их не поддерживают функции надежности, которые изначально поддерживаются системами реляционных БД. Эти характеристики надежности можно обобщить как атомарность, согласованность, изоляцию и долговечность. Это означает, что NoSQL, которые не поддерживают эти функции, обеспечивают согласованность торговли для производительности и масштабируемости.
Чтобы поддерживать функции обеспечения надежности и согласованности, разработчики должны реализовать собственный проприетарный код, который увеличивает сложность системы. Это ограничивает число приложений, которые могут полагаться на NoSQL для безопасных и надежных транзакций, например, банковские системы.
Применение базы данных NoSQL

Академические работники, инженеры, архитекторы программного обеспечения, дизайнеры приложений и программисты требуют более глубокого знания структур данных, которые ранее не требовались для реляционных баз данных. Лидерами рынка являются - Hadoop и MongoDB, вслед за "Кассандрой", "Редисом", CouchDB и "Риаком". Современные исследования показывают, что есть два продукта NOSQL, которые доминируют над системными инженерами, архитекторами программного обеспечения, разработчиками среди десятка аналогичных технологий – это MongoDB и Hadoop.
Рынок показывает, что крупные компании используют новые методологии разработки баз данных NoSQL и интегрируют их в свои продукты (Oracle, IBM). Рынок БД понемногу превращается в стандарт PasS, Redis и MongoDB, Edlich. Такие продукты, как Neo4j, MongoDb и CouchDb, стали объектом поддержки и инвестирования венчурного капитала.