Содержательный и алфавитный подход к измерению информации
Развитие компьютерной техники в новом информационном веке вызывает множество дополнительных вопросов, открывает новые возможности и знания. Но вместе с этим и возникает множество дилемм, которые необходимо разрешить. Так, например, изучая компьютерную технику, важно понимать, как она обрабатывает, запоминает и передает файлы, что такое кодирование данных и в каком формате осуществляется измерение информации. Но главным предметом обсуждения становится вопрос о том, какие существуют основные подходы к измерению информации. Примеры и пояснения каждого аспекта будут подробно описаны в данной статье.
Информация в компьютерной науке
Чтобы начинать разбираться в информационных подходах хранения данных, прежде необходимо узнать, что в компьютерной сфере представляет информация и что она показывает. Ведь если взять информатику как науку, то ее основным объектом изучения является именно информация. Само слово латинского происхождения и в переводе на наш язык означает "ознакомление", "объяснение", "сведение". Каждая наука использует разные определения данного понятия. В компьютерной сфере это все те сведения о различных явления и объектах, окружающих нас, которые уменьшают меру неопределенности и степень нашего незнания о них. Но, чтобы хранить все файлы, данные, символьные знаки в электронной вычислительной машине, необходимо знать алгоритм их перевода в бинарный вид и существующие единицы замера количества данных. Алфавитный подход к измерению информации показывает, как именно компьютерная машина преобразовывает символы в бинарный код ноликов и единичек.
Кодирование информации электронной вычислительной машиной
Компьютерная техника способна распознавать, обрабатывать, запоминать и передавать только информационные данные в двоичном коде. Но если это аудиозапись, текст, видео, графическое изображение, как машина способна разные типы данных преобразовывать в бинарный тип? И как они в таком виде хранятся в памяти? На эти вопросы ответы можно найти, если вы знаете алфавитный подход к определению количества информации, содержательный аспект и техническую суть кодирования.
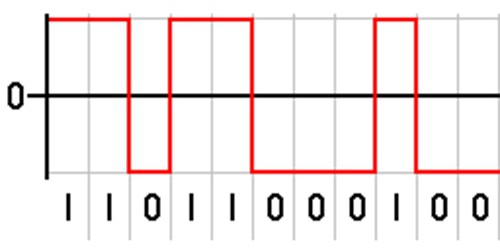
Кодирование информации состоит в том, чтобы зашифровать символы в бинарный код, состоящий из знаков "0" и "1". Это технически просто организовать. Сигнал есть, если стоит единица, ноль указывает на обратное. Некоторые задаются вопросом о том, почему компьютер не может, как и человеческий мозг, сохранять сложные числа, ведь они меньше по размеру. Но электронной вычислительной технике легче оперировать огромным бинарным кодом, нежели хранить в своей памяти сложные числа.
Системы исчисления в компьютерной сфере
Мы привыкли считать от 1 до 10, слагать, вычитать, умножать и делать различные операции над числами. Компьютер же способен оперировать только двумя числами. Но делает это за доли миллисекунд. Как компьютерной машиной производится кодирование и декодирование символов? Это достаточно простой алгоритм, который можно рассмотреть на примере. Алфавитный подход к измерению информации, единицы измерения данных мы рассмотрим немного позже, после того, как станет понятной суть кодирования и декодирования данных.
Существует множество компьютерных программ, которые наглядно осуществляют перевод систем исчисления или текстовой строки в двоичный код и обратно.
Мы же осуществим расчеты вручную. Кодирование информации производится обычным делением на 2. Итак, допустим, у нас есть десятичное число 217. Нам необходимо преобразовать его в двоичный код. Для этого делим его на число 2 до того момента, пока в остатке не получится ноль или единица.
- 217/2=108 с остатком 1. Отдельно выписываем остатки, именно они и будут создавать наш окончательный ответ.
- 108/2=54. Здесь остатком является число 0, так как 108 нацело делится. Не забываем помечать себе остатки. Ведь если потерять хоть одну цифру, изначальное число уже будет другим.
- 54/2=27, остаток 0.
- 27/2=13, записываем 1 в остаток. Наши числа из остатка создают бинарный код, который необходимо считывать в обратном порядке.
- 13/2=6. Здесь единица в остатке, выписываем ее.
- 6/2=3 с остатком 0. В конечном ответе цифр должно быть на одну больше, чем всех действий, произведенных вами.
- 3/2=1 с остатком 1. Записываем остаток и число 1, которое является окончательным делением.
Если оформлять ответ, начиная с цифры в первом действии, в результате получится 10011011, но это неверно. Бинарное число необходимо переписать в обратном порядке. Вот окончательный результат перевода числа: 11011001. Содержательный и алфавитный подход к измерению информации используют данные именно такого формата для хранения и передачи. Двоичный код записывается в кодовую таблицу и хранится там, пока не понадобится вывести его на экран монитора. Затем осуществляется перевод информации в привычный для нас вид, называемый декодированием.
На картинке хорошо виден алгоритм перевода из бинарного вида в десятичный код. Он осуществляется по простой формуле. Первую цифру кода умножаем на 2 в степени 0, прибавляем к ней следующую цифру, умноженную на 2 в большей степени, и так далее. В результате, как видно из картинки, получаем то же число, что и изначальное при кодировании.
Алфавитный подход к измерению информации: суть, единицы
Чтобы измерить объем данных в текстовой последовательности символов, необходимо использовать существующий подход. Здесь не важно содержание текста, главное - количественное соотношение знаков. Благодаря этому аспекту высчитывается величина текстового сообщения, закодированного на компьютере. В соответствии с данным подходом количественная величина текста пропорциональна числу знаков, введенных с клавиатуры. Благодаря этому метод измерения информационного объема зачастую называют объемным. Символы могут быть совершенно разными по величине. Понятно, что такие цифры как 0 и 1 несут 1 бит информации, а буквы, знаки препинания, пробел – другой вес. Можно посмотреть ASCII-таблицу, чтобы узнать бинарный код того или иного знака. Чтобы посчитать необходимый нам текстовый объем, нужно сложить вес всех знаков – составных частей всего текста. Это и есть алфавитный подход к определению количества информации.
В компьютерной науке существует множество терминов, которыми все чаще оперируют в обиходе. Так, алфавит в информатике означает набор всех символов, включая скобки, пробел, знаки препинания, символы кириллицы, латиницы, которые являются ничем иным как текстовой составной частью. Здесь имеют место два определения, по которым и будет рассчитываться данная величина.
1. Благодаря первому определению можно рассчитать встречаемость знаков в текстовом сообщении, когда их вероятность появления совершенно разная. Так, можно сказать, что некоторые буквы в русских словах появляются очень редко, например, «ъ» или «ё».
2. Но в некоторых случаях целесообразнее высчитать нужную нам величину, представив равновероятностное появление каждого символа. И тут будет использоваться другая формула расчета.
В этом и заключается алфавитный подход к измерению информации.
Равновероятностная встречаемость знаков в текстовом файле
Чтобы объяснить данное определение, необходимо допустить, что все знаки в тексте или сообщении появляются с одинаковой частотой. Чтобы посчитать, какой объем памяти они занимают в компьютере, необходимо окунуться в теорию вероятности и простых логических выводов.
Допустим, на экране монитора выведен текст. Перед нами стоит задача посчитать, какой объем памяти компьютера он занимает. Пусть текст состоит из 100 символов. Получается, что вероятность появления одной буквы, символа или знака будет составлять одну сотую часть всего объема. Если почитать книгу по теории вероятности, можно найти такую достаточно простую формулу, которая точно определит числовую величину шанса появления того или иного знака в любой позиции текста.
Наверное, доказательство формул и теорем не всем будет интересно, поэтому, учитывая формулы известных ученых, выводится расчетное выражение:
i=log2(1/p)=log2N(бит); 2i=N,
где i – это та величина, которую нам необходимо узнать, p – числовое значение возможности возникновения знака в текстовой позиции, N в большинстве случаев равняется 2, ведь компьютерная машина кодирует данные в бинарный код, состоящий из двух величин.
Алфавитный объемный подход к измерению информации предполагает, что вес одного символьного знака равняется 1 биту – минимальной единице измерения. По формуле можно определить, чему равняется байт, килобайт, мегабайт и др.
Разная вероятность встречаемости символов в тексте
Если предполагать, что знаки появляются с разной частотой (соответственно, и в любой позиции текста их вероятность появления различна), тогда можно сказать, что их информационный вес тоже разный. Необходимо вычислять по другой формуле измерение информации. Алфавитный подход тем и универсален, что предполагает как равную, так и разную возможность частоты встречаемости знака в тексте. Мы не будем затрагивать сложную формулу расчета данной величины с учетом различной вероятности встречаемости символа. Необходимо понимать, что такие буквы, как "ъ", "х", "ф", "ч", в русских словах встречаются гораздо реже. Поэтому возникает необходимость считать частоту появления по другой формуле. Проведя некоторые расчеты, ученые пришли к выводу, что информационный вес редко попадающихся символов гораздо больше, нежели вес букв, которые часто встречаются. Чтобы вычислить объем текста, необходимо учитывать величину повторений каждого символа и его информационный вес, а также размер алфавита.
Измерение информации: тонкости содержательного аспекта
Можно не учитывать алфавитный подход к измерению информации. Информатика предлагает еще один аспект измерения данных – содержательный. Тут уже решается немного другая задача. Допустим, человек, сидящий за компьютером, получает информацию о явлении или каком-нибудь предмете. Заранее понятно, что он не знает ничего, поэтому есть некое число возможных или ожидаемых вариантов. После прочтения сообщения неопределенность пропадает, остается один вариант, величину которого и необходимо высчитать. Обращаемся к вспомогательной формуле. Величина будет исчисляться в минимальной единице – битах. Как и алфавитный подход к измерению количества информации, правильная формула будет выбрана с учетом 2-х возможных ситуаций: разной и равной вероятности встречаемости событий.
События, встречаемые с равной вероятностью
Как и в случае, когда применяется объективный алфавитный подход к измерению информации, искомая формула при содержательном подходе рассчитывается с учетом уже известной закономерности, которую вывел ученый Хартли:
2i=N,
где i – это величина события, которую нам необходимо найти, а N – число событий, встречаемых с равновероятностной частотой. Величина i считается в минимальной единице исчисления – битах. Можно i выразить через логарифм.
Пример расчета равновероятностного события
Допустим, у нас на тарелке лежит 64 пельменя, в одном из которых спрятан сюрприз вместо мяса. Необходимо посчитать, сколько информации содержит событие, когда вытянули именно этот пельмень с сюрпризом, то есть осуществить измерение информации. Алфавитный подход такой же простой, как и объективный. В двух случаях использовалась бы одна и та же формула для расчета количественного объема информационных материалов. Подставляем известную формулу величины: 2i=64=26. Результат: i=6 бит.
Измерение информации с учетом различной вероятности появления события
Допустим, у нас есть некоторое событие с вероятностью появления p. Будем считать, что величина i, рассчитываемая в битах, - это число, характеризирующее тот факт, что событие произошло. Исходя из этого, можно утверждать, что величины можно рассчитать по существующей формуле: 2i=1/p.
Отличия алфавитного и содержательного подходов к информационному измерению
Чем объемный подход отличается от содержательного? Ведь формулы расчета величин количества информации совершенно одни и те же. Разница в том, что алфавитный аспект можно использовать, если вы работаете с текстами, а содержательный позволяет решать любые задачи теории вероятности, высчитывать объем информации некого события с учетом его вероятного появления.
Выводы
Алфавитный подход к измерению информации так же, как и содержательный, дает возможность узнать, какие единицы измерения данных и какой объем будут занимать текстовые знаки или любые другие сведения. Мы можем перевести любые текстовые и числовые файлы, сообщения в компьютерный код и обратно, при этом всегда знать, сколько памяти они будут занимать в компьютерной вычислительной машине.