Кодирование информации - невероятно широкая область знаний. Разумеется, она напрямую связана с развитием цифровой техники. Во многих современных учебных заведениях самая популярная тема - кодирование информации. Сегодня мы изучим основные трактовки этого явления применительно к различным аспектам работы компьютеров. Постараемся ответить на вопрос: "Кодирование - это процесс, метод, инструмент или все эти явления одновременно?"
Нули и единицы
Практически любые типы данных, которые отображаются на экране компьютера, так или иначе представляют собой двоичный код, состоящий из нулей и единиц. Это самый простейший, "низкоуровневый" способ шифрования информации, позволяющий ПК обрабатывать данные. Двоичный код универсален: его понимают все без исключения компьютеры (собственно, для этого он и был создан - чтобы стандартизировать пользование информацией в цифровой форме).

Базовая единица, которую использует двоичное кодирование, - это бит (от словосочетания "binary digit" - "двойная цифра"). Он равен либо 0, либо 1. Как правило, биты по отдельности не используются, а объединяются в 8-значные последовательности - байты. В каждом из них, таким образом, может содержаться до 256 комбинаций из нулей и единиц (2 в 8-й степени). Для записи значительных объемов информации используются, как правило, не единичные байты, а более масштабные величины - с приставками "кило", "мега", "гига", "тера" и т. д., каждая из которых в 1000 раз больше предыдущей.
Кодирование текста
Самый распространенный вид цифровых данных - это текст. Каким образом осуществляется его кодирование? Это достаточно легко объяснимый процесс. Буква, знак препинания, цифра или символ может кодироваться посредством одного или нескольких байтов, то есть компьютер видит их как уникальную последовательность нулей и единиц, а затем, в соответствии с заложенным алгоритмом распознавания, отображает на экране. Есть два основных мировых стандарта "шифрования" компьютерного текста - ASCII и UNICODE.
В системе ASCII каждый знак кодируется только одним байтом. То есть посредством этого стандарта можно "зашифровать" до 256 знаков - что более чем достаточно для отображения символов большинства алфавитов мира. Конечно, все существующие на сегодня национальные буквенные системы не поместятся в этот ресурс. Поэтому для каждого алфавита создана собственная "подсистема" шифрования. Происходит кодирование информации с помощью знаковых систем, адаптированных к национальным образцам письменности. Однако каждая из этих систем, в свою очередь, является составной частью глобального стандарта ASCII, принятого на международном уровне.
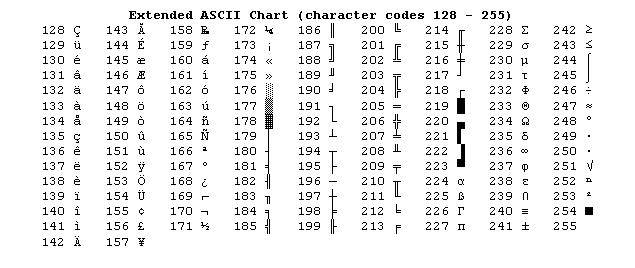
В рамках системы ASCII этот самый ресурс из 256 знаков делится на две части. Первые 128 - это символы, отведенные под английский алфавит (буквы от a до z), а также цифры, основные знаки препинания и некоторые другие символы. Вторые 128 байт зарезервированы, в свою очередь, под национальные буквенные системы. Это и есть "подсистема" для неанглийских алфавитов - русского, хинди, арабского, японского, китайского и многих других.
Каждая из них представлена в виде отдельной таблицы кодировки. То есть может получиться (и, как правило, это происходит) так, что одна и та же последовательность битов будет отвечать за разные буквы и символы в двух отдельных "национальных" таблицах. Более того, в связи с особенностями развития IT-сферы в разных странах даже они отличаются. Например, для русского языка наиболее распространены две системы кодирования: Windows-1251 и KOI-8. Первая появилась позже (равно как и сама созвучная ей операционная система), но теперь многими IT-специалистами используется в первоочередном порядке. Поэтому компьютер, чтобы на нем можно было гарантированно читать русский текст, должен уметь корректно распознавать обе таблицы. Но, как правило, никаких проблем с этим нет (если на ПК стоит современная операционная система).
Методы кодирования текстов все время совершенствуются. Кроме "однобайтной" системы ASCII, способной оперировать только 256 значениями для символов, есть также и "двухбайтная" система UNICODE. Несложно подсчитать, что она позволяет осуществлять текстовое кодирование в количестве, равном 2 в 16-й степени, то есть 65 тыс. 536. В ней, в свою очередь, есть ресурсы для одновременного кодирования практических всех существующих национальных алфавитов мира. Использование UNICODE не менее распространено, чем задействование "классического" стандарта ASCII.
Кодирование графики
Выше мы определили, каким образом "шифруются" тексты и как при этом используются байты. Как обстоит дело с цифровыми фотографиями и картинками? Также довольно просто. Аналогично тому, как это происходит с текстом, главную роль в кодировании компьютерной графики играют все те же байты.
Процесс построения цифровых изображений в целом схож с механизмами, на основе которых работает телевизор. На экране ТВ, если приглядеться, картинка состоит из множества отдельных точек, которые в совокупности формируют распознаваемые на некотором расстоянии глазом фигуры. Телевизионная матрица (или ЭЛТ-проектор) получает из передатчика горизонтальные и вертикальные координаты каждой из точек и постепенно выстраивает изображение. Компьютерный принцип кодировки графики работает точно так же. "Шифрование" изображений байтами основано на задании каждой из экранных точек соответствующих координат (а также цвета каждой из них). Это если говорить простым языком. Разумеется, графическое кодирование - это процесс намного более сложный, чем то же текстовое.
Метод задания точкам соответствующих координат и цветовых параметров называется "растровым". Аналогично именуются многие файловые форматы компьютерной графики. Координаты каждой из точек изображения, а также их цвет записываются в один или несколько байтов. От чего зависит их количество? Главным образом от того, сколько оттенков цвета предстоит "зашифровывать". Один байт, как известно, - это 256 значений. Если для выстраивания картинки нам хватит такого количества оттенков - обойдемся этим ресурсом. В частности, в нашем распоряжении может оказаться 256 оттенков серого цвета. И этого будет достаточно, чтобы кодировать практически любые черно-белые изображения. В свою очередь, для цветных изображений данного ресурса будет явно недостаточно: человеческий глаз, как известно, способен различать до нескольких десятков миллионов цветов. Поэтому необходим "запас" не в 256 значений, а в сотни тысяч раз больше. Отчего для кодирования точек задействуется не один байт, а несколько: по существующим на сегодня стандартам их может быть 16 (можно "зашифровать" 65 тыс. 536 цветов) или 24 (16 млн 777 тыс. 216 оттенков).
В отличие от текстовых стандартов, многообразие которых сопоставимо с количеством мировых языков, с графикой дела обстоят несколько проще. Самые распространенные форматы файлов (такие как JPEG, PNG, BMP, GIF и т. д.) распознаются на большинстве компьютеров в целом одинаково хорошо.
Нет ничего сложного с тем, чтобы понять, по каким принципам осуществляется кодирование графической информации. 9 класс любой средней российской школы, как правило, включает в себя курс компьютерной науки, где подобные технологии раскрываются довольно подробно очень простым и понятным языком. Есть также и специализированные программы обучения для взрослых - их организуют вузы, лицеи, либо также школы.

Поэтому современному российскому человеку есть где почерпнуть знания о кодах, имеющих практическую значимость в части компьютерной графики. А если хочется ознакомиться с базовыми знаниями самостоятельно, можно обзавестись доступными учебными материалами. К таковым можно отнести, к примеру, главу "Кодирование графической информации (9 класс, учебник "Информатика и ИКТ" под авторством Угринович Н. Д.).
Кодирование звуковых данных
Компьютер регулярно используется для прослушивания музыки и других аудиофайлов. Так же как и в случае с текстом и графикой, любой звук на ПК - это все те же байты. Они, в свою очередь, "дешифруются" аудиокартой и иными микросхемами и преобразуются в слышимый звук. Принцип здесь примерно тот же, что и в случае с пластинками граммофона. В них, как известно, каждый звук соответствует микроскопической бороздке на пластике, которая распознается считывателем, а затем озвучивается. В компьютере все похоже. Только роль бороздок играют байты, в природе которых, так же как и в случае с текстом и картинками, лежит двоичное кодирование.
Если в случае с компьютерными изображениями единичным элементом выступает точка, то при записи звука это так называемый "отсчет". В нем, как правило, прописывается два байта, генерирующих до 65 тыс. 536 звуковых микроколебаний. Однако, в отличие от того, как это происходит при построении изображений, для улучшения качества звука осуществляется не добавление дополнительных байтов (их, очевидно, и так более чем достаточно), а увеличение количества "отсчетов". Хотя в некоторых аудиосистемах байтов используется и меньшее, и большее число. Когда осуществляется кодирование звука, то стандартной единицей измерения "плотности потока" байтов выступает одна секунда. То есть микроколебания, зашифрованные при помощи 8 тыс. отсчетов в секунду, будут, очевидно, более низкого качества, чем последовательность звуков, закодированных посредством 44 тыс. "отсчетов".
Международная стандартизация аудиофайлов, так же как и в случае с графикой, хорошо развита. Есть несколько типовых форматов звукового медиа - MP3, WAV, WMA, которыми пользуются во всем мире.
Кодирование видео
Своего рода "гибридная схема", при которой шифрование звука объединяется с кодированием картинок, используется в компьютерных видеороликах. Обычно фильмы и клипы состоят из двух типов данных - это как таковой звук и сопутствующий ему видеоряд. Как "шифруется" первый компонент, мы рассказали выше. Со вторым чуть сложнее. Принципы здесь иные, чем включает в себя рассмотренное выше графическое кодирование. Но благодаря универсальности "концепции" байтов, суть механизмов вполне понятна и логична.
Вспомним, как устроена кинопленка. Она представляет собой не что иное как последовательность отдельных кадров (их, как правило, 24). Совершенно аналогичным образом устроены компьютерные видеоролики. Каждый кадр - это картинка. О том, как она строится при помощи байтов, мы определили выше. В свою очередь, в видеоряде присутствует определенная область кода, позволяющая связывать отдельные кадры между собой. Своего рода цифровой заменитель кинопленки. Отдельной единицей измерения видеопотока (аналогичной точкам для картинок и отсчетам для звука, как и в "пленочном" формате кино и роликов), принято считать кадр. Последних в одной секунде, в соответствии с принятыми стандартами, может быть 25 или 50.
Так же как и в случае с аудио, есть распространенные международные стандарты видеофайлов - MP4, 3GP, AVI. Производители кино и роликов стараются выпускать образцы медиа, совместимые с как можно большим количеством компьютеров. Указанные форматы файлов - в числе самых популярных, они открываются практически на любом современном ПК.
Сжатие данных
Хранение компьютерных данных осуществляется на различных носителях - дисках, флешках и т. д. Как мы уже сказали выше, байты, как правило, "обрастают" приставками "мега", "гига", "тера" и т. д. В некоторых случаях величина закодированных файлов такова, что разместить их при имеющихся ресурсах на диске невозможно. Тогда используются различного рода методы сжатия данных. Они, по сути, также представляют собой кодирование. Это - еще одна возможная трактовка термина.
Существует два основных механизма сжатия данных. По первому из них последовательность битов записывается в "упакованном" виде. То есть компьютер не может прочитать содержимое файлов (воспроизвести его как текст, картинку или видео), если не осуществит процедуру "распаковки". Программа, которая выполняет сжатие данных таким способом, называется архиватор. Принцип ее работы достаточно прост. Архивацию данных как один из самых популярных методов, при помощи которых можно осуществить кодирование информации, информатика школьного уровня изучает в обязательном порядке.
Как мы помним, процесс "шифрования" файлов в байтах стандартизован. Возьмем стандарт ASCII. Чтобы, скажем, зашифровать слово "привет", нам понадобится 6 байт, исходя из количества букв. Именно столько пространства файл с этим текстом займет на диске. Что будет, если мы напишем слово "привет" 100 раз подряд? Ничего особенного - для этого нам понадобится 600 байт, соответственно, столько же места на диске. Однако мы можем использовать архиватор, что создаст файл, в котором посредством гораздо меньшего количества байт будет "зашифрована" команда, выглядящая примерно так: "привет умножить на 100". Подсчитав количество букв в этом сообщении, приходим к выводу, что для записи такого файла нам понадобится всего лишь 19 байт. И столько же места на диске. При "распаковке" же архивного файла происходит "дешифрование", и текст приобретает исходный вид со "100 приветами". Таким образом, используя специальную программу, которая задействует особый механизм кодирования, мы можем сэкономить на диске существенный объем пространства.
Вышеописанный процесс достаточно универсален: какие бы ни использовались знаковые системы, кодирование информации с целью сжатия всегда возможно посредством архивации данных.
Что представляет собой второй механизм? В какой-то мере он схож с тем, что применяется в архиваторах. Но принципиальное его отличие в том, что сжатый файл вполне может отображаться компьютером без процедуры "распаковки". Как работает этот механизм?
Как мы помним, в исходном виде слово "привет" занимает 6 байт. Однако мы можем пойти на хитрость и записать его так: "првт". Выходит 4 байта. Все, что остается сделать - это "научить" компьютер добавлять в процессе отображения файла те буквы, которые мы убрали. Надо сказать, что на практике "учебный" процесс организовывать и не нужно. Базовые механизмы распознавания недостающих символов заложены в большинстве современных программ для ПК. То есть основная часть файлов, с которыми мы имеем дело каждый день, так или иначе уже "зашифрована" по этому алгоритму.
Безусловно, есть и "гибридные" системы кодирования информации, позволяющие осуществлять сжатие данных при одновременном задействовании обоих вышеописанных подходов. И они, скорее всего, будут еще более эффективны с точки зрения экономии дискового пространства, чем каждый по отдельности.
Конечно, оперируя словом "привет", мы изложили лишь основные принципы работы механизмов сжатия данных. В реальности они гораздо сложнее. Различные системы кодирования информации могут предлагать невероятно сложные механизмы "компрессии" файлов. Однако мы видим, за счет чего можно добиться экономии дискового пространства, практически не прибегая к ухудшению качества информации на ПК. Особенно значима роль сжатия данных при использовании картинок, аудио и видео - эти виды данных более других требовательны к ресурсам диска.
Какие еще бывают "коды"?
Как мы уже сказали в самом начале, кодирование - это сложносоставное явление. Разобравшись с базовыми принципами кодирования цифровых данных, основанных на байтах, мы можем затронуть другую область. Связана она с использованием компьютерных кодов в несколько иных значениях. Здесь под "кодом" мы будем понимать не последовательность нулей и единиц, а совокупность различных букв и символов (которые, как мы уже знаем, и так сделаны из 0 и 1), имеющую практическую значимость для жизни современного человека.
Программный код
В основе работы любой компьютерной программы - код. Написан он на языке, понятном компьютеру. ПК, расшифровывая код, выполняет те или иные команды. Отличительная особенность компьютерной программы от другого типа цифровых данных в том, что содержащийся в ней код способен "дешифровать" себя сам (пользователю лишь достаточно запустить этот процесс).

Еще одна особенность программ - в относительной гибкости используемого кода. То есть давать компьютеру одни и те же задания человек может, пользуясь достаточно большим набором "фраз", а при необходимости - и на другом языке.
Код разметки документов
Другая практически значимая область применения буквенного кода - создание и форматирование документов. Как правило, простого отображения знаков на экране недостаточно с точки зрения практической значимости пользования ПК. В большинстве случаев текст должен быть построен при помощи шрифта определенного цвета и размера, сопровождаться дополнительными элементами (такими как, например, таблицы). Все эти параметры задаются, так же как и в случае с программами, на особых языках, понятных компьютеру. ПК, распознав "команды", отображает документы именно так, как желает пользователь. Кроме того, тексты могут быть одинаково отформатированы, подобно тому, как это происходит с программами, при помощи различных наборов "фраз" и даже на разных языках.
Однако есть принципиальное отличие между кодами для документов и компьютерных программ. Оно состоит в том, что первые не способны дешифровать себя сами. Для открытия файлов с отформатированными текстами всегда требуются сторонние программы.
Шифрование данных
Еще одна интерпретация термина "код" применительно к компьютерам - это шифрование данных. Выше мы употребляли это слово как синоним термину "кодирование", и это допустимо. В данном случае под шифрованием мы будем понимать иного рода явление. А именно кодирование цифровых данных с целью запрещения к ним доступа со стороны других людей. Защита компьютерных файлов - важнейшее направление деятельности в IT-сфере. Это фактически отдельная научная дисциплина, ее включает в себя также и школьная информатика. Кодирование файлов с целью пресечения несанкционированного доступа - это задача, важность которой излагается гражданам современных стран уже в детстве.

Как устроены механизмы, с помощью которых осуществляется шифрование данных? В принципе, так же просто и понятно, как и все предыдущие, рассмотренные нами. Кодирование - это процесс, легко объяснимый с точки зрения базовых принципов логики.
Предположим, нам необходимо передать сообщение "Иванов идет к Петрову" так, чтобы никто не смог его прочитать. Мы доверяем зашифровать сообщение компьютеру и видим результат: "10-3-1-15-16-3-10-5-7-20-11-17-6-20-18-3-21". Этот код, конечно, весьма нехитрый: каждая цифра соответствует порядковому номеру букв нашей фразы в алфавите. "И" стоит на 10 месте, "В" - на 3, "А" - на 1, и т. д. Но современные компьютерные системы кодирования могут шифровать данные так, что подобрать к ним ключ будет невероятно сложно.