














Структура данных – программная единица, позволяющая сберегать и обрабатывать массу однотипных или же логически связанных сведений в вычислительных устройствах. Если требуется добавить, найти, изменить или удалить сведения, структура предоставит определенный пакет опций, что составляет ее интерфейс.
Что включает в себя понятие структуры данных?

Этот термин может иметь несколько близких, но все же отличительных значений. Это:
- абстрактный тип;
- реализация абстрактного вида информации;
- экземпляр типа данных, к примеру, определенный список.
Если говорить о структуре данных в контексте функционального программирования, то это особенная единица, что сберегается при изменениях. О ней неформально можно сказать как о единой структуре, несмотря на то что могут иметься различные версии.
Что формирует структуру?
Структура данных формируется с помощью типов информации, ссылок и операций над ними в определенном языке программирования. Стоит сказать, что разные виды структур подходят для осуществления разных приложений, некоторые, к примеру, обладают совершенно узкой специализацией и подходят только для производства установленных задач.
Если взять B-деревья, то они обычно подходят для формирования баз данных и только для них. В этот же час хеш-таблички применяются еще повсеместно на практике для создания различных словарей, к примеру, для демонстрации доменных наименований в интернет-адресах ПК, а не только для формирования баз.
Во время разработки того или иного программного обеспечения сложность реализации и качество функциональности программ напрямую зависят от правильного применения структур данных. Такое понимание вещей дало толчок к разработке формальных методик разработки и языков программирования, где структуры, а не алгоритмы ставятся на лидирующие позиции в архитектуре программы.
Стоит отметить, что многие языки программирования обладают установленным типом модульности, что позволяет структурам с данными безопасно использоваться в различных приложениях. Яркими примерами являются языки Java, C# и C++. Сейчас классическая структура используемых данных представлена в стандартных библиотеках языков программирования или непосредственно она встроена уже в сам язык. К примеру, это структура хэш-таблицы встроена в Lua, Python, Perl, Ruby, Tcl и другие. Широко применяется стандартная библиотека шаблонов в C++.
Сравниваем структуру в функциональном и императивном программировании

Стоит сразу оговорится, что проектировать структуры для функциональных языков сложнее, чем для императивных, как минимум на это есть две причины:
- Фактически все структуры часто применяют на практике присваивание, которое в чисто функциональном стиле не используется.
- Функциональные структуры – это гибкие системы. В императивном программировании старые версии просто заменяются на новые, а в функциональном все работает, как работало. Иными словами, в императивном программировании структуры являются эфемерными, а в функциональном они постоянные.
Что включает в себя структура?
Часто данные, с которыми работают программы, сберегаются во встроенных в применяемом языке программирования массивах, константе или в переменной длине. Массив – это простейшая структура со сведениями, однако для решения некоторых задач требуется большая эффективность некоторых операций, потому применяются иные структуры (сложнее).
Простейший массив подходит для частого обращения к установленным компонентам по индексам и их изменению, а удаление элементов из средины функционирует за принципом O(N)O(N). Если вам требуется удалить элементы, чтобы разрешить определенные задачи, то придется воспользоваться иной структурой. К примеру, бинарное дерево (std::set) позволяет делать это по O(logN)O(logN), однако оно не поддерживает работу с индексами, выполняется исключительно поочередный обход элементов и их поиск по значению. Таким образом, можно сказать, что структура отличается операциями, что она способна выполнять, а также скоростью их проделывания. Для примера стоит рассмотреть простейшие структуры, что не дают выгоды в эффективности, но имеют точно установленный набор поддерживаемых операций.
Стек
Это один из типов структур данных, представленный в виде ограниченного простейшего массива. Классический стек поддерживает всего лишь три опции:
- Внести элемент в стек (Сложность: O(1)O(1)).
- Извлечение элемента из стека (Сложность: O(1)O(1)).
- Проверка, пустой ли стек или нет (Сложность: O(1)O(1)).
Чтобы пояснить принцип работы стека, можно применить на практике аналогию с банкой печенья. Представьте, что на дне посудины лежит несколько печенюшек. Наверх вы можете положить еще пару кусочков или же вы можете, наоборот, взять одну печеньку сверху. Остальные печеньки будут закрыты верхними, и вы про них ничего не будете знать. Вот так дела обстоят и со стеком. Для описания понятия применяется аббревиатура LIFO (Last In, First Out), которая подчеркивает, что компонент, попавший внутрь стека последним, будет первым же и извлечен из него.
Очередь
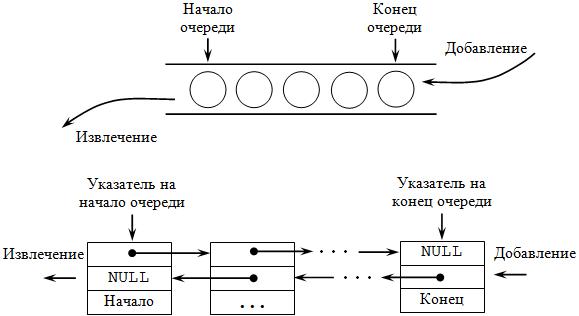
Это еще один тип структуры данных, что поддерживает тот же набор опций, что и стек, однако у него противоположная семантика. Для описания очереди применяется аббревиатура FIFO (First In, First Out), потому как вначале извлекается элемент, что добавлен был раньше всех. Название структуры говорит за себя – принцип работы полностью совпадает с очередями, что можно увидеть в магазине, супермаркете.
Дек
Это еще один вид структуры данных, который еще называют очередью с двумя концами. Опция поддерживает следующий набор операций:
- Внести элемент в начало (Сложность: O(1)O(1)).
- Извлечь компонент из начала (Сложность: O(1)O(1)).
- Внесение элемента в конец (Сложность: O(1)O(1)).
- Извлечение элемента из конца (Сложность: O(1)O(1)).
- Проверка, пустой ли дек (Сложность: O(1)O(1)).
Списки
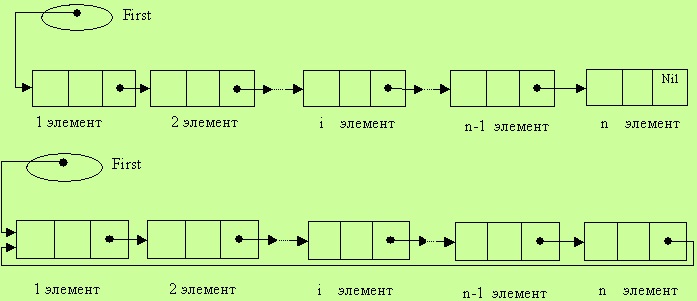
Данная структура данных определяет последовательность линейно связанных компонентов, для которых разрешены операции добавления компонентов в любое место списка и его удаление. Линейный список задается указателем на начало списка. Типичные операции над списками: обход, поиск конкретного компонента, вставка элемента, удаление компонента, объединение двух списков в единое целое, разбивка списка на пару и так далее. Стоит оговориться, что в линейном списке, помимо первого, имеется предыдущий компонент для каждого элемента, не включая последний. Это означает, что компоненты списка находятся в упорядоченном состоянии. Да, обработка такого списка не всегда удобна, ведь нет возможности продвижения в противоположную сторону — от конца списка к началу. Однако в линейном списке можно поэтапно пройтись по всем составляющим.
Еще существуют кольцевые списки. Это такая же структура, что и линейный список, однако она имеет дополнительную связь между первым и последним компонентами. Другими словами, следующим за последним элементом является первый компонент.
В этом списке элементы равноправны. Выделение первого и последнего – это условность.
Деревья
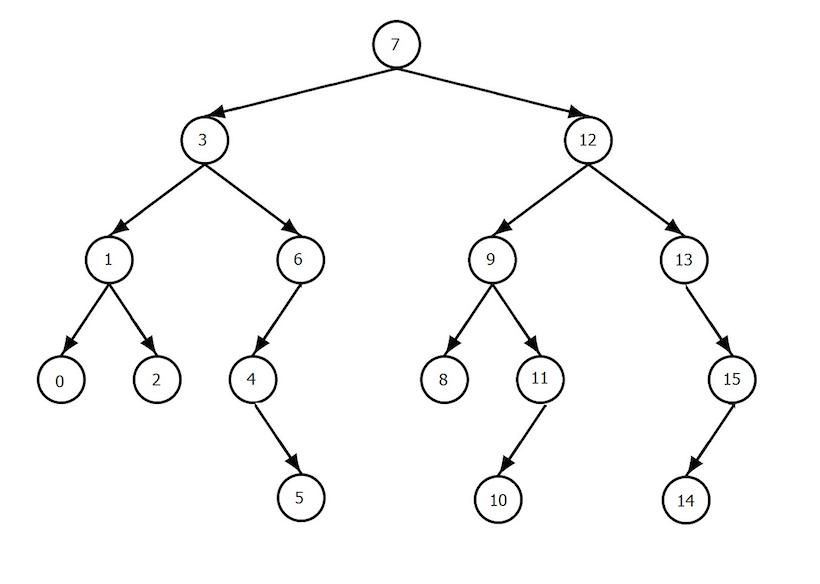
Это совокупность компонентов, что именуются узлами, в котором есть главный (один) компонент в виде корня, а все остальные разбиты на множество непересекающихся элементов. Каждое множество является деревом, а корень каждого древа – потомком корня дерева. Другими словами, все компоненты соединены между собой отношениями предок–потомок. Как результат можно наблюдать иерархическую структуру узлов. Если узлы не имеют потомка, то они называются листьями. Над деревом определены такие операции, как: добавление компонента и его удаление, обход, поиск компонента. Особую роль в информатике играют бинарные деревья. Что это такое? Это частный случай дерева, где каждый узел может иметь не больше пары потомков, являющихся корнями левого и правого поддерева. Если дополнительно для узлов дерева выполняется еще условие, что все значения компонентов левого поддерева меньше значений корня, а значения компонентов правого поддерева больше корня, то такое дерево именуется деревом бинарного поиска, и предназначается оно для быстрого нахождения элементов. Как же работает алгоритм поиска в таком случае? Искомое значение сравнивается со значением корня, и в зависимости от результата поиск либо завершается, либо продолжается, но исключительно в левом или правом поддереве. Общее число операций сравнения не станет превосходить высоту дерева (это наибольшее число компонентов на пути от корня до одного из листьев).
Графы
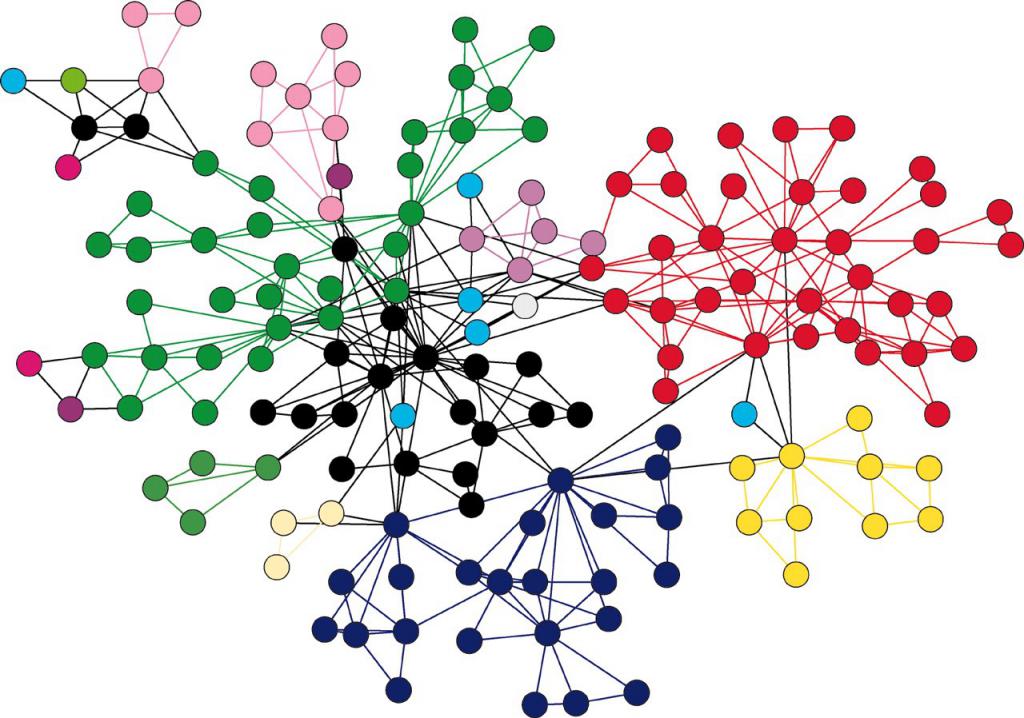
Графы – это совокупность компонентов, что именуются вершинами вместе с комплексом отношений между данными вершинами, которые называются ребрами. Графическая интерпретация данной структуры представлена в виде множества точек, что отвечают за вершины, а некоторые пары соединены линиями или стрелками, что соответствует ребрам. Последний случай говорит о том, что граф нужно называть ориентированным.
Графами можно описывать объекты какой угодно структуры, они являются главным средством для описания сложных структур и функционирования всех систем.
Детальней об абстрактной структуре

Для построения алгоритма требуется провести формализацию данных или, иными словами, необходимо привести данные к определенной информационной модели, что уже исследована и написана. Как только модель будет найдена, то можно утверждать, что установлена абстрактная структура.
Это основная структура данных, демонстрирующая признаки, качества объекта, взаимосвязь между компонентами объекта и операции, что возможно осуществить над ним. Основная задача – поиск и отображение форм представления сведений, комфортных для компьютерной корректировки. Стоит оговориться сразу, что информатика как точная наука действует с формальными объектами.
Анализ структур данных производится следующими объектами:
- Целые и вещественные числа.
- Логические значения.
- Символы.
Для обработки на компьютере всех элементов существуют соответствующие алгоритмы и структуры данных. Типичные объекты можно объединить в сложные структуры. Можно добавить операции над ними, правила к определенным компонентам этой структуры.
Структура организации данных включает в себя:
- Векторы.
- Динамические структуры.
- Таблицы.
- Многомерные массивы.
- Графы.
Если все элементы выбраны удачно, то это будет залогом формирования эффективных алгоритмов и структур данных. Если применять на практике аналогию структур и реальных объектов, то можно эффективно разрешать существующие задачи.
Стоит заметить, что все структуры организации данных существуют и по отдельности в программировании. Над ними много трудились еще в восемнадцатых и девятнадцатых веках, когда еще и в помине не было вычислительной машины.
Возможно разрабатывать алгоритм в понятиях абстрактной структуры, однако для реализации алгоритма на определенном языке программирования потребуется отыскать методику для ее представления в типах данных, операторах, что поддерживаются конкретным языком программирования. Для создания структур, таких как вектор, табличка, строка, последовательность, во многих языках программирования имеются классические типы данных: одномерный или двухмерный массив, строка, файл.
Какие есть методические рекомендации по работе со структурами?
Мы разобрались с характеристиками структур данных, теперь стоит уделить больше внимания пониманию понятия структуры. При решении абсолютно любой задачи требуется работать с какими-то данными, чтобы произвести операции над информацией. У каждой задачи есть свой набор операций, однако некоторый набор применяется на практике чаще для решения разнообразных заданий. В таком случае полезно придумать определенный способ организации информации, что позволит выполнять эти операции как можно эффективнее. Как только такой способ появился, можно считать, что у вас появился «черный ящик», в котором будут сберегаться данные определенного рода и который станет выполнять те или иные операции с данными. Это позволит отвлечься от деталей и полностью сконцентрироваться на характерных особенностях задачи. Данный «черный ящик» может быть реализован любым образом, при этом необходимо стремиться к как можно более продуктивной реализации.
Кому это необходимо знать?
Ознакомится с информацией стоит начинающим программистам, которые желают отыскать свое место в этой сфере, но не знают, куда податься. Это основы в каждом языке программирования, потому будет не лишним узнать сразу же о структурах данных, а после работать с ними на конкретных примерах и с определенным языком. Не следует забывать, что каждую структуру возможно охарактеризовать логическими и физическими представлениями, а также совокупностью операций над этими представлениями.
Не забывайте: если говорите о той или иной структуре, то имейте в виду ее логическое представление, ведь физическое представление полностью сокрыто от «внешнего наблюдателя».
Кроме того, имейте в виду, что логическое представление совершенно не зависит от языка программирования и от вычислительной машины, а физическое, наоборот, зависит от трансляторов и вычислительной техники. К примеру, двумерный массив в "Фортране" и "Паскале" можно представить идентичным образом, а физическое представление в одной и той же вычислительной машине на этих языках будет отличаться.
Не спешите начинать учить конкретные структуры, лучше всего понять их классификацию, ознакомиться со всеми в теории и желательно на практике. Стоит помнить, что изменчивость – это важный признак структуры, и он указывает на статическое, динамическое или же полустатическое положение. Изучайте основы, прежде чем приступить к более глобальным вещам, это вам поможет в дальнейшем развитии.











