















Бинарное дерево поиска — структуризированная база данных, содержащая узлы, две ссылки на другие узлы, справа и слева. Узлы — это объект класса, имеющего данные, а NULL — знак, обозначающий конец дерева.
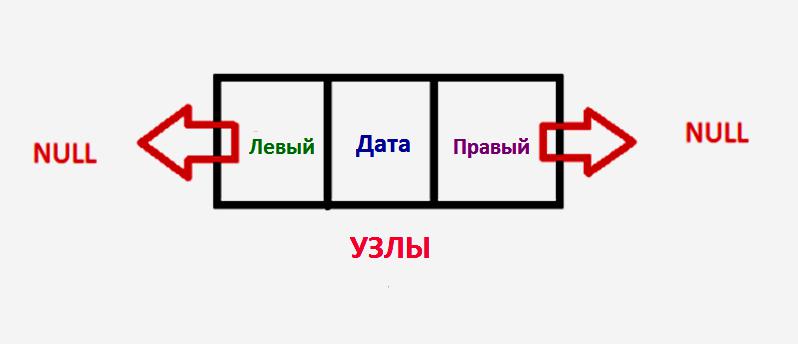
Его часто обозначают как BST, обладающий специальным свойством: узлы больше корня располагаются справа от него, а меньшие — слева.
Общая теория и терминология
У бинарного дерева поиска каждый узел, исключая корень, связан направленным ребром от одного узла к другому, который называют родительским. Каждый из них может быть подключен к произвольному числу узлов, называемых дочерними. Узлы без "детей" называются листьями (внешние узлы). Элементы, которые не являются листьями, называются внутренними. Узлы с одним и тем же родителем — это братья и сестры. Самый верхний узел называется корнем. В BST назначают элемент каждому узлу и убеждаются, что для них выполнено специальное свойство.
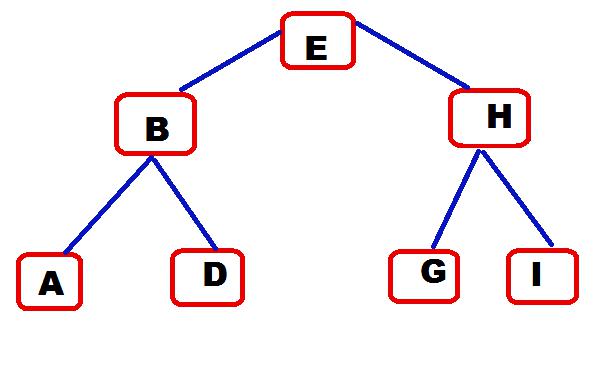
Терминологии дерева:
- Глубина узла - число ребер, определенное от корня до него.
- Высота узла — число ребер, определенное от него до самого глубокого листа.
- Высота дерева — определяется высотой корня.
- Бинарное дерево поиска — специальная конструкция, она обеспечивает наилучшее соотношение высоты и количества узлов.
- Высота h с N узлами не более O (log N).
Можно это легко доказать, подсчитав узлы на каждом уровне, начиная с корня, считая, что он содержит наибольшее количество из них: n = 1 + 2 + 4 + ... + 2 h-1 + 2 h = 2 h + 1 - 1 Решая это по h, получим h = O (log n).
Преимущества дерева:
- Отражают структурные отношения данных.
- Используются для представления иерархий.
- Обеспечивают эффективную установку и поиск.
- Деревья — очень гибкие данные, позволяющие перемещать поддеревья с минимальными усилиями.
Метод поиска
В общем случае, чтобы определить, находится ли это значение в BST, начинают бинарное дерево поиска c его корня и определяют, соответствует ли оно требованиям:
- находиться в корне;
- находиться в левом поддереве root;
- в правом поддереве root.
Если ни один базовый регистр не выполняется, рекурсивный поиск выполняется в соответствующем поддереве. На самом деле есть два базовых варианта:
- Дерево пустое — return false.
- Значение находится в корневом узле — return true.
Нужно обратить внимание, что бинарное дерево поиска c развитой схемой начинает поиск всегда по пути от корня к листу. В худшем случае, он проходит весь путь к листу. Поэтому наихудшее время пропорционально длине самого длинного пути от корня к листу, что является высотой дерева. В общем, это когда нужно знать, сколько времени требуется для поиска в качестве функции количества значений, хранящихся в дереве.
Другими словами, существует связь между количеством узлов в BST и высотой дерева, зависящая от его «формы». В худшем случае узлы обладают только одним дочерним элементом, а сбалансированное бинарное дерево поиска по существу является связанным списком. Например:
50
/
10
\
15
\
30
/
20
Это дерево имеет 5 узлов и высоту = 5. Для поиска значений в диапазоне 16–19 и 21–29 потребуется следующий путь от корня до листа (узел, содержащий значение 20), т. е. потребуется время, пропорциональное количеству узлов. В лучшем случае все они имеют 2-х детей, а листья расположены на одной глубине.
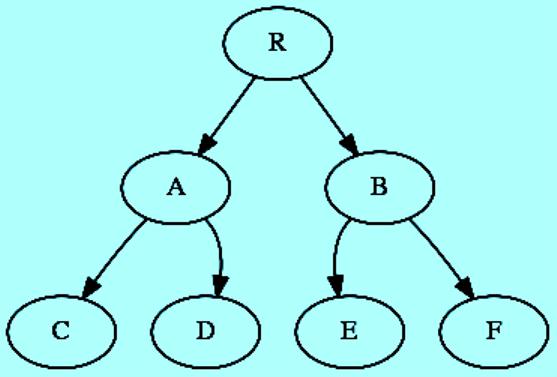
Это бинарное дерево поиска имеет 7 узлов и высоту = 3. В общем случае дерево, подобное этому (полное дерево), будет иметь высоту примерно log 2 (N), где N - количество узлов в дереве. Значение log 2 (N) — это количество раз (2), когда можно разделить N, прежде чем будет достигнут ноль.
Подводя итог: наихудшее время, необходимое для поиска в BST, равно O (высота дерева). В худшем случае «линейное» дерево - это O (N), где N - количество узлов в дереве. В лучшем случае «полное» дерево - это O (log N).
Двоичная вставка BST
Задаваясь вопросом, где должен быть расположен новый узел в BST, нужно понимать логику, он должен быть помещен туда, где найдет его пользователь. Кроме того, нужно запомнить правила:
- Дубликаты не допускаются, попытка вставить дублирующее значение вызовет исключение.
- Метод public insert использует вспомогательный рекурсивный метод «помощник» для фактической вставки.
- Узел, содержащий новое значение, всегда вставляется как лист в BST.
- Открытый метод insert возвращает void, но вспомогательный метод возвращает BSTnode. Он делает это, чтобы обрабатывать случай, когда узел, переданный ему, равен нулю.
В общем случае вспомогательный метод указывает на то, что если исходное бинарное дерево поиска пустое, результатом является дерево с одним узлом. В противном случае результатом будет указатель на тот же узел, который был передан в качестве аргумента.
Удаление в бинарном алгоритме
Как и следовало ожидать, удаление элемента связано с поиском находящего узел, содержащий значение, которое нужно удалить. В этом коде есть несколько вещей:
- BST использует вспомогательный, перегруженный метод удаления. Если искомый элемент не находится в дереве, то в итоге вспомогательный метод будет вызываться с n == null. Это не считается ошибкой, дерево в этом случае просто не меняется. Вспомогательный метод удаления возвращает значение — указатель на обновленное дерево.
- Когда удаляется лист, при удалении из бинарного дерева поиска устанавливается соответствующий дочерний указатель его родителя на нуль или корень в null, если удаляемый узел является корнем, и у него нет детей.
- Нужно обратить внимание на то, что вызов для удаления должен быть одним из следующих: root = delete (root, key), n.setLeft (delete (n.getLeft (), key)), n.setRight (delete (n.getRight (), key)). Таким образом, во всех трех случаях правильно, когда метод delete просто возвращает null.
- Когда поиск узла, содержащий удаляемое значение, завершается успешно, то существует три варианта: узел для удаления — лист (не имеет детей), у удаляемого узла есть один ребенок, у него есть двое детей.
- Когда удаляемый узел имеет один дочерний элемент, можно просто заменить его потомком, возвращая указатель на дочерний элемент.
- Если удаляемый узел имеет ноль или 1 дочерний элемент, то метод удаления будет «следовать по пути» от корня к этому узлу. Таким образом, наихудшее время пропорционально высоте дерева, как и для поиска, так и вставки.
Если удаляемый узел имеет двух детей, выполняются следующие шаги:
- Найти удаляемый узел, следуя по пути от корня к нему.
- Найти наименьшее значение v в правом поддереве, продолжая движение по пути к листу.
- Рекурсивно удалить значение v, следовать по тому же пути, что и в пункте 2.
- Таким образом, в худшем случае путь от корня до листа выполняется дважды.
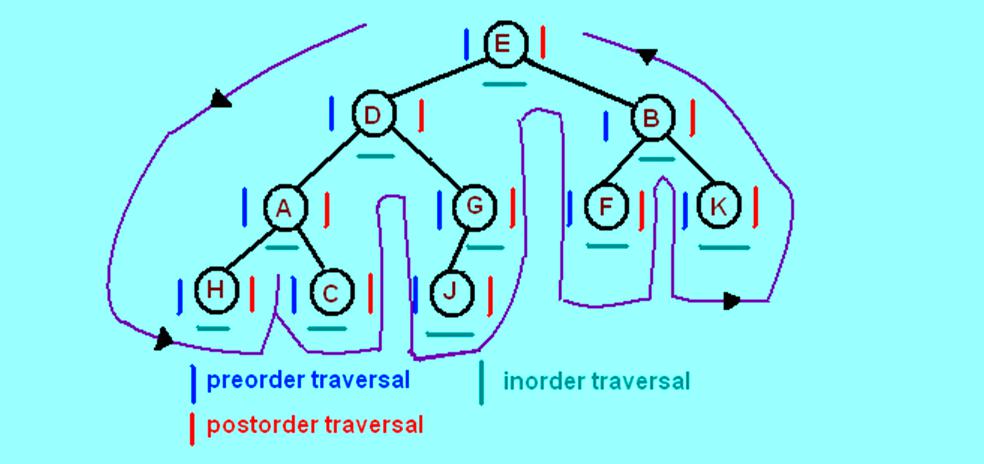
Порядок траверсов
Обход (Traversal) — это процесс, который посещает все узлы в дереве. Поскольку бинарное дерево поиска си является нелинейной структурой данных, уникального обхода не существует. Например, иногда несколько алгоритмов обхода сгруппированы по следующим двум видам:
- пересечение глубины;
- первый проход.
Существует только один вид пересечения ширины — обход уровня. Этот обход посещает узлы по уровням вниз и слева, сверху и направо.
Существуют три разных типа пересечений по глубине:
- Прохождение PreOrder — сначала посетить родителя, а затем левого и правого ребенка.
- Прохождение InOrder — посещение левого ребенка, потом родителя и правильного ребенка.
- Обход PostOrder — посещение левого дочернего элемента, затем правильного ребенка, а далее родителя.
Пример для четырех обходов бинарного дерева поиска:
- PreOrder - 8, 5, 9, 7, 1, 12, 2, 4, 11, 3.
- InOrder - 9, 5, 1, 7, 2, 12, 8, 4, 3, 11.
- PostOrder - 9, 1, 2, 12, 7, 5, 3, 11, 4, 8.
- LevelOrder - 8, 5, 4, 9, 7, 11, 1, 12, 3, 2.
На рисунке показан порядок посещений узлов. Число 1 обозначает первый узел в конкретном обходе, а 7 — последний узел.
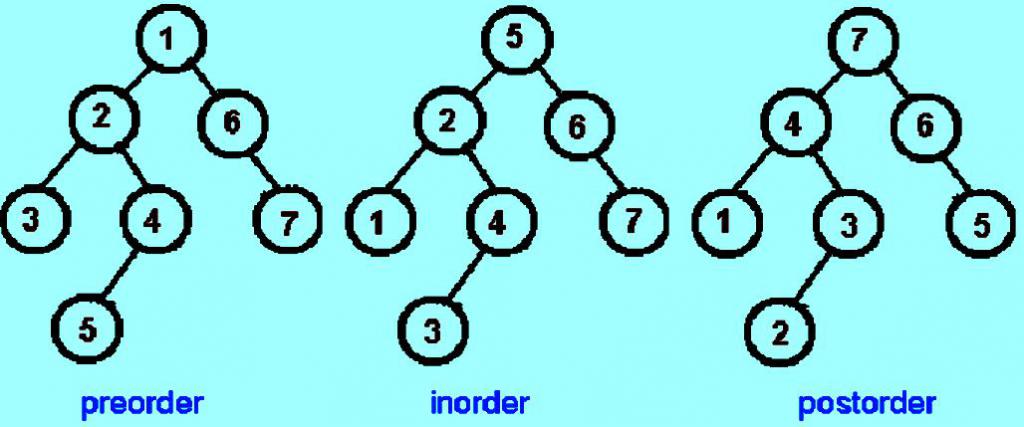
Эти общие обходы можно представить в виде единого алгоритма, предположив, что каждый узел посещают три раза. Euler тур - прогулка вокруг бинарного дерева, где каждое ребро рассматривается как стена, которую пользователь не можете пересечь. В этой прогулке каждый узел будет посещаться либо слева, либо внизу, либо справа. Тур Euler, в котором посещаются узлы слева, вызывает обход предлога. Когда посещаются узлы ниже, получают обход по порядку. И когда посещаются узлы справа — получают пооперационный обход.
Навигация и отладка
Чтобы облегчить перемещение по дереву, создают функции, которые предварительно проверяют, являются ли они левым или правым дочерним элементом. Чтобы изменить положение узла, должен быть простой доступ к указателю в родительском узле. Правильно реализовать дерево очень сложно, поэтому нужно знать и применять процессы отладки. У бинарного дерева поиска c реализацией часто встречаются указатели, которые фактически направление хода не указывают.
Чтобы во всем этом разобраться, используется функция, которая проверяет, может ли дерево быть правильным, и помогает найти много ошибок. Например, проверяет, является ли родительский узел узлом ребенка. С помощью assert (is_wellformed (root)) многие ошибки могут быть преждевременно перехвачены. Используя пару заданных контрольных точек внутри этой функции можно также точно определить, какой указатель ошибочен.
Функция Konsolenausgabe
Эта функция полностью сбрасывает дерево на консоль и поэтому очень полезна. Порядок выполнение цели по выводу дерева:
- Для этого сначала нужно определить, какая информация будет выводиться через узел.
- И также нужно знать, насколько широким и высоким является дерево, чтобы учесть, сколько нужно оставить свободного места.
- Следующие функции вычисляют эту информацию для дерева и каждого поддерева. Поскольку можно писать в консоль только по строкам, также нужно будет выводить дерево по строкам.
- Теперь нужен другой способ вывода всего дерева, а не только построчный.
- С помощью функции дампа можно прочитать дерево и значительно улучшить алгоритм вывода, поскольку это касается скорости.
Тем не менее эту функцию будет сложно использовать на больших деревьях.
Конструктор копирования и деструктор

Поскольку дерево не является тривиальной структурой данных, лучше реализовать конструктор копирования, деструктор и оператор присваивания. Деструктор легко реализовать рекурсивно. Для очень больших деревьев он может обрабатывать «переполнение кучи». В этом случае его формулируют итеративно. Идея заключается в том, чтобы удалить лист, представляющий наименьшее значение всех листьев, поэтому он находится на левой стороне дерева. Отрезание первых листьев создает новые, и дерево сжимается, пока оно, наконец, перестанет существовать.
Конструктор копирования также может быть реализован рекурсивно, но нужно быть осторожным, если исключение вылетает. Иначе дерево быстро становится запутанным и подверженным ошибкам. Вот почему предпочитают итеративную версию. Идея состоит в том, чтобы пройти через старое и новое дерево, как это делается в деструкторе, клонируя все узлы, которые находятся в старом дереве, но не новые.
С помощью этого метода реализация бинарного дерева поиска всегда находится в здоровом состоянии и может быть удалена деструктором даже в незавершенном состоянии. Если возникает исключение, нужно только дать команду деструктору удалить полуготовое дерево. Оператор присваивания может быть легко реализован с использованием Copy & Swap.
Создание двоичного дерева поиска
Оптимальные бинарные деревья поиска невероятно эффективны, если они управляются должным образом. Некоторые правила для двоичных поисковых деревьев:
- Родительский узел имеет самое большее 2 дочерних узла.
- Левый дочерний узел всегда меньше родительского узла.
- Правильный дочерний узел всегда больше или равен родительскому узлу.

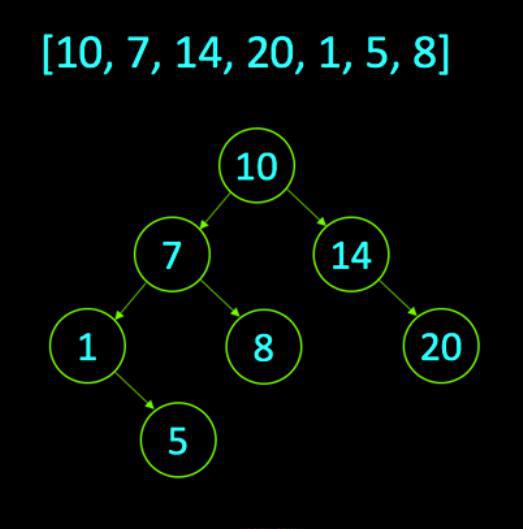
Массив, который будет использоваться для построения бинарного дерева поиска:
- Базовый целочисленный массив, состоящий из семи значений, которые находятся в несортированном порядке.
- Первое значение в массиве равно 10, поэтому первым шагом при построении дерева будет создание 10 корневого узла, как показано здесь.
- С набором корневых узлов все остальные значения будут дочерними элементами этого узла. Ссылаясь на правила первым шагом, который будет предпринят для добавления 7 в дерево, будет сравнение его с корневым узлом.
- Если значение 7 меньше 10, оно станет левым дочерним узлом.
- Если значение 7 больше или равно 10, оно будет перемещаться вправо. Поскольку известно, что 7 меньше 10, его обозначают как левый дочерний узел.
- Рекурсивно выполнить сравнения для каждого элемента.
- Следуя той же схеме, выполняют то же сравнение с 14 значением в массиве.
- Сравнивая значение 14 с корневым узлом 10, зная, что 14 — правильный ребенок.
- Пробираясь через массив, приходят к 20.
- Начинают со сравнения массива с 10, что больше. Таким образом, двигаются вправо и сравнивают его с 14, он больше 14 и не имеет детей справа.
- Теперь есть значение 1. Следуя той же схеме, что и другие значения, сравнивают с 1 по 10, переместившись влево и сравнивая с 7 и, наконец, с 1 левым дочерним элементом 7-го узла.
- При значении 5 сравнивают его с 10. Поскольку 5 меньше 10, проходят влево и сравнивают его с 7.
- Зная, что 5 меньше 7, продолжают вниз по дереву и сравнивают 5 с 1 значением.
- Если 1 не имеет дочерних узлов, а 5 — больше 1, то 5 — правильный ребенок из 1 узла.
- Наконец, вставляют значение 8 в дерево.
- При 8 меньше, чем 10, перемещают его влево и сравниваем его с 7, 8 больше 7, поэтому перемещают его вправо и завершают дерево, что делает 8 правильным ребенком 7.
Получаем и оцениваем простую элегантность оптимальных бинарных деревьев поиска. Как и многие другие темы в программировании, сила двоичных деревьев поиска зависит от их способности разрешать разбиение данных на небольшие связанные компоненты. С этого момента можно работать с полным набором данных организованным образом.
Потенциальные проблемы двоичного поиска

Деревья двоичного поиска хороши, но есть несколько предостережений, о которых нужно помнить. Они обычно эффективны только в том случае, если сбалансированы. Сбалансированное дерево — это дерево,в котором разница между высотами поддеревьев любого узла в дереве не больше единицы. Рассмотрим пример, который может помочь разъяснить правила. Представим, что массив начинается, как сортируемый.
Если попытаться запустить алгоритм дерева двоичного поиска в этом дереве, он будет выполнять точно так же, как если бы просто повторять массив, пока не будет найдено искомое значение. Сила двоичного поиска заключается в возможности быстро отфильтровать ненужные значения. Когда дерево не сбалансировано, он не даст таких преимуществ, как сбалансированное дерево.
Очень важно изучить данные, с которыми работает пользователь, когда создается двоичное дерево поиска. Можно интегрировать подпрограммы, такие как рандомизация массива, прежде чем реализовать бинарное дерево поиска для целых чисел, чтобы сбалансировать его.
Примеры расчета двоичного поиска
Нужно определить, какое дерево получится, если будет вставлено 25 в следующее дерево двоичного поиска:
10
/ \
/ \
5 15
/ / \
/ / \
2 12 20
Когда вставляют x в дерево T, которое еще не содержит x, ключ x всегда помещается в новый лист. В связи с чем новое дерево будет иметь вид:
10
/ \
/ \
5 15
/ / \
/ / \
2 12 20
\
\
25
Какое дерево будет получено, если вставить 7 в следующее дерево двоичного поиска?
10
/ \
/ \
5 15
/ / \
/ / \
2 12 20
Ответ:
10
/ \
/ \
/ \
5 15
/ \ / \
/ \ / \
2 7 12 20
Двоичное дерево поиска может использоваться для хранения любых объектов. Преимущество использования двоичного дерева поиска вместо связанного списка состоит в том, что если дерево разумно сбалансировано и больше похоже на «полное» дерево, чем «линейное», вставка, поиск, и все операции удаления могут быть реализованы для запуска в O (log N) времени.











