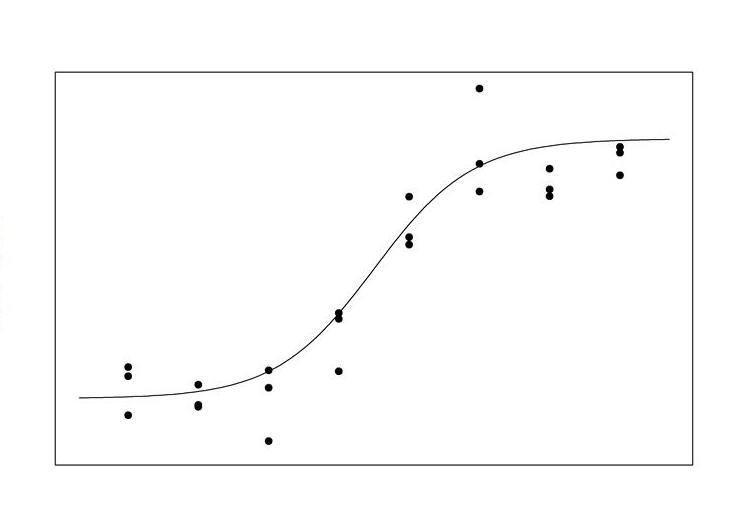
Статистическая модель представляет собой математическую проекцию, которая воплощает в себе набор различных предположений относительно генерации некоторых выборочных данных. Данный термин представляют часто в значительно идеализированной форме.
Допущения, выраженные в статистической модели, показывают комплект вероятностных распределений. Многие из которых, как подразумевается, правильно аппроксимируют распределение, из которого отбирается определенный комплект информации. Распределения вероятностей, свойственные статистическим моделям,— это то, что выделяет проекцию от иных математических модификаций.
Общая проекция
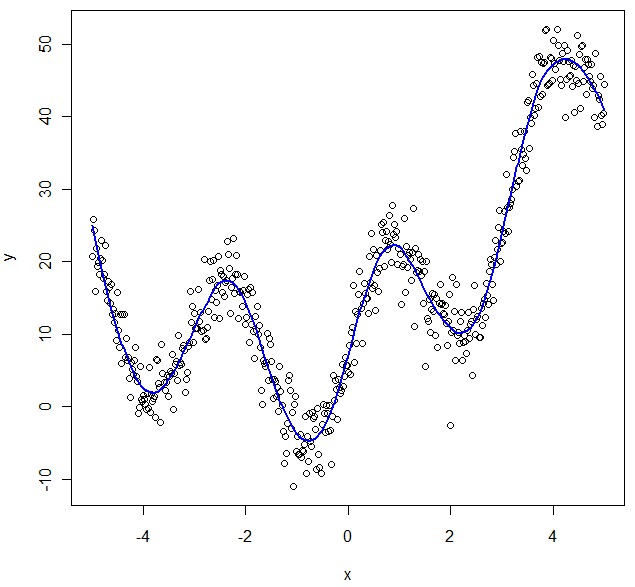
Математическая модель представляет собой описание системы с использованием определенных понятий и языка. Они применяются в естественных науках (таких как физика, биология, наука о Земле, химия) и инженерных дисциплинах (таких как информатика, электротехника), а также в социальных науках (таких как экономика, психология, социология, политология).
Модель может помочь объяснить систему и изучить влияние различных компонентов, а также сделать прогнозы поведения.
Математические модели могут принимать различные формы, включая динамические системы, статистические проекции, дифференциальные уравнения или теоретико-игровые параметры. Эти и другие типы могут пересекаться, причем данная модель включает в себя множество абстрактных структур. В целом математические проекции могут включать в себя и логические компоненты. Во многих случаях качество научной области зависит от того, насколько хорошо математические модели, разработанные с теоретической стороны, согласуются с результатами повторяемых экспериментов. Отсутствие согласия между теоретическими процессами и экспериментальными измерениями часто приводит к важным достижениям по мере разработки более совершенных теорий.
В физических науках традиционная математическая модель содержит большое количество следующих элементов:
- Управляющие уравнения.
- Дополнительные подмодели.
- Определение уравнений.
- Учредительные уравнения.
- Допущения и ограничения.
- Начальные и граничные условия.
- Классические ограничения и кинематические уравнения.
Формула
Статистическая модель, как правило, задается математическими уравнениями, которые объединяют одну либо несколько случайных величин и, возможно, других закономерно, вытекающих, переменных. Подобным образом проекция считается «формальным понятием концепции».
Все статистические проверки гипотез и статистические оценки заработаны из математических моделей.
Введение
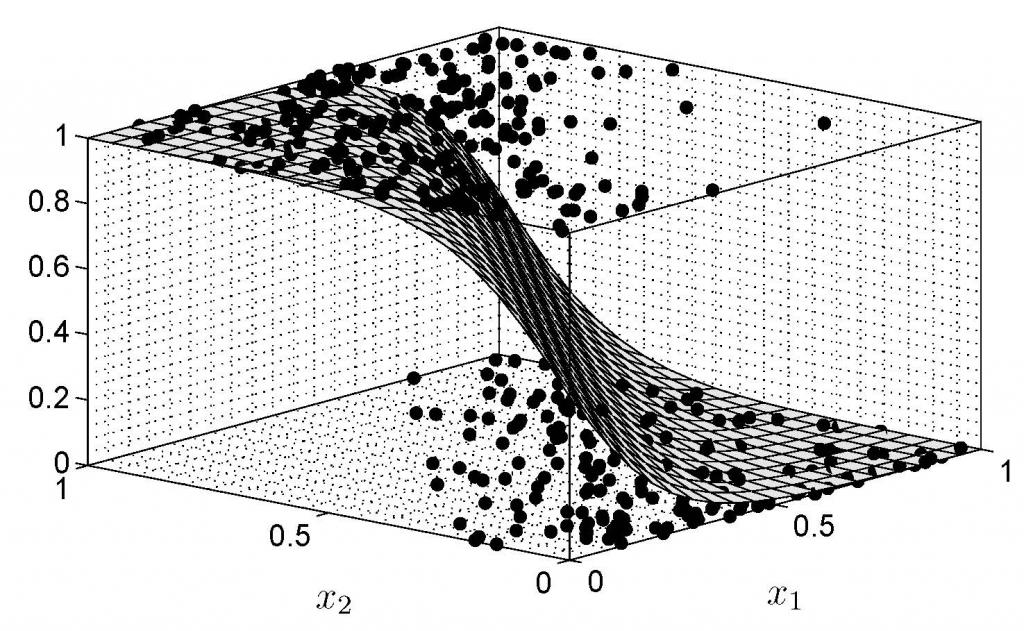
Неформально статистическая модель может рассматриваться как допущение (или набор допущений) с определенным свойством: оно позволяет вычислять вероятность любого события. В качестве примера можно рассмотреть пару обычных шестигранных кубиков. Необходимо изучить два различных статистических предположения о кости.
Первое допущение заключается в следующем:
Для каждого из кубиков вероятность выпадения одного из числа (1, 2, 3, 4, 5, и 6) составляет: 1/6.
Из этого предположения можно вычислить вероятность обоих кубиков: 1:1/6×1/6=1/36.
В более общем смысле можно рассчитать вероятность любого события. Однако стоит понимать, что невозможно рассчитать вероятность какого-либо другого нетривиального события.
Только лишь первое мнение собирает статистическую математическую модель: вследствие того что только лишь с одним допущением можно определить вероятность каждого действия.
В приведенном выше образце с первоначальным дозволением определить возможность события легко. С некоторыми другими примерами расчет может быть трудным либо даже нереальным (к примеру, это может требовать множество лет вычислений). Для человека, составляющего модель статистического анализа, подобная сложность считается неприемлемой: осуществление расчетов не должно быть фактически неосуществимым и теоретически невозможным.
Формальное определение
В математических терминах статистическая модель системы обычно рассматривается как пара (S, P), где S это набор возможных наблюдений, то есть пространство выборки, и P это набор распределений вероятностей на S.
Интуиция этого определения заключается в следующем. Предполагается, что существует «истинное» распределение вероятностей, вызванное процессом, который генерирует определенные данные.
Набор
Именно он определяет параметры модели. Параметризация, как правило, требует, чтобы различные значения приводили к отличным распределениям, т. е.
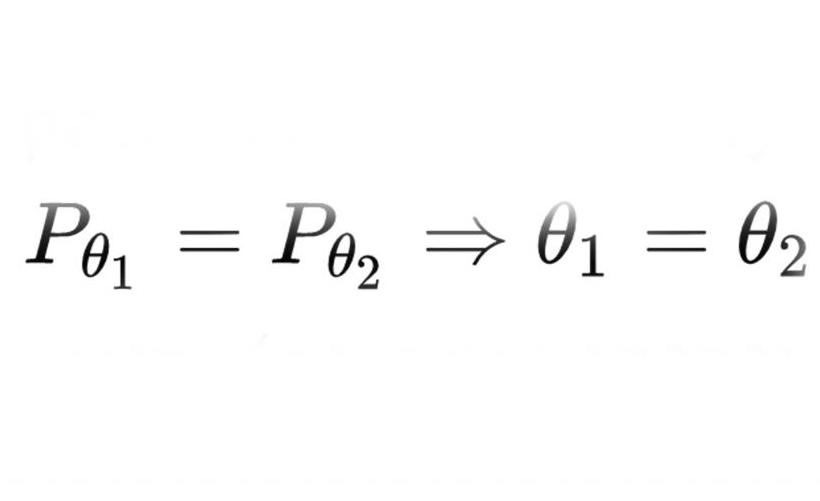
должен держаться (другими словами, он должен быть инъективным). Параметризация, которая соответствует требованию, называется идентифицируемой.
Пример
Предположим, что есть какое-то количество школьников, которые имеют разный возраст. Рост ребенка будет стохастически связан с годом рождения: например, когда школьнику 7 лет, это влияет на вероятность роста, только так, что человек будет выше 3 сантиметров.
Можно формализовать этот подход в модель прямолинейной регрессии, к примеру, таким образом: высота i = b 0 + b 1agei + εi, где b 0 - пересечение, b 1 - параметр, на который умножается возраст при получении мониторинга возвышенности. Это термин погрешности. То есть это предполагает, что рост предсказывается возрастом с определенной ошибкой.
Допустимая форма обязана отвечать всем точкам информации. Таким образом, прямолинейное направление (уровень i = b 0 + b 1agei) не способно быть уравнением для модели данных — если она четко не отвечает абсолютно всем пунктам. То есть все без исключения сведения безупречно возлежат на линии. Участник погрешностиεi обязан быть введен в равенство, чтобы форма соответствовала абсолютно всем пунктам информации.
Чтобы сделать статистический вывод, сначала нужно принять некоторые вероятностные распределения для ε i. Например, можно предположить, что распределения ε i имеют гауссову форму с нулевым средним. В этом случае модель будет иметь 3 параметра: b 0, b 1 и дисперсию распределения Гаусса.
Можно формально указать модель в виде (S, Р).
В этом примере модель определяется указанием S и поэтому можно сделать некоторые предположения, имеющие отношение к P. Есть два варианта:
Этот рост может быть аппроксимирован линейной функцией возраста;
Что ошибки в приближении распределяются как внутри гауссова.
Общие замечания
Статистические параметры моделей — это особый класс математической проекции. Что отличает один вид от другого? Так это то, что статистическая модель недетерминирована. Таким образом, в ней, в отличие от математических уравнений, определенные переменные не имеют определенных значений, а вместо этого обладают распределением возможностей. То есть отдельный переменные считаются стохастическими. В приведенном ранее примере ε является стохастической переменной. Без нее проекция была бы детерминированной.
Построения статистической модели часто используются, даже если материальный процесс считается детерминированным. К примеру, подбрасывание монет в принципе является предопределяющим действием. Однако все же это в большинстве случаев моделируется как стохастический (через процесс Бернулли).
Согласно Konishi и Kitagawa, существует три цели для статистической модели:
- Предсказания.
- Добыча информации.
- Описание стохастических структур.
Размер проекции
Предположим, что есть модель статистического прогнозирования,
Модель называется параметрической, если О имеет конечное измерение. В решении необходимо написать, что
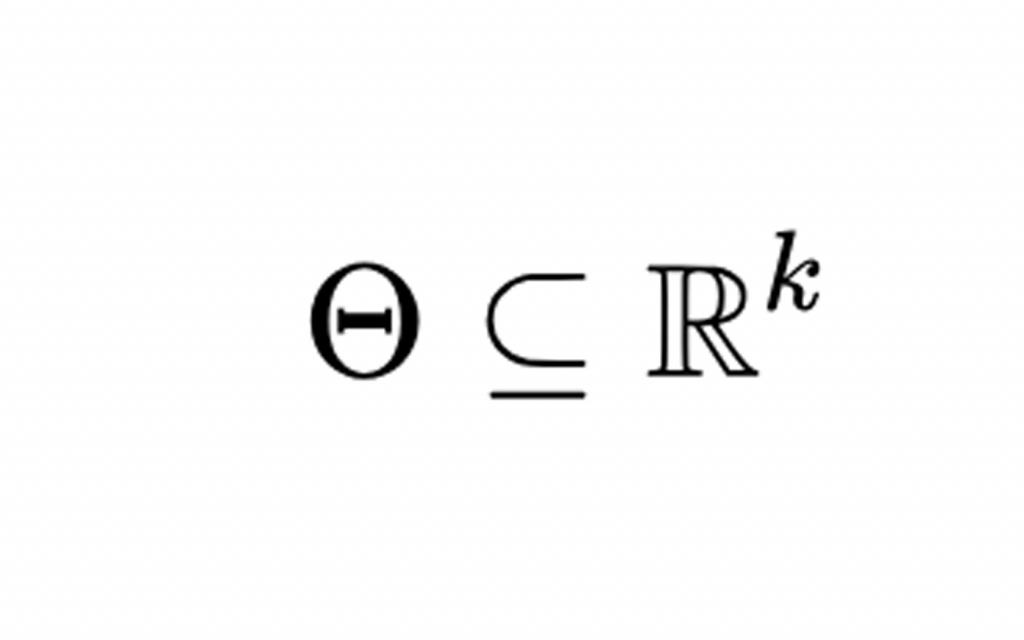
где k - это положительное целое число (R обозначает любые действительные числа). Здесь k называется размерностью модели.
В качестве примера можно предположить, что все данные возникают из одномерного гауссовского распределения:
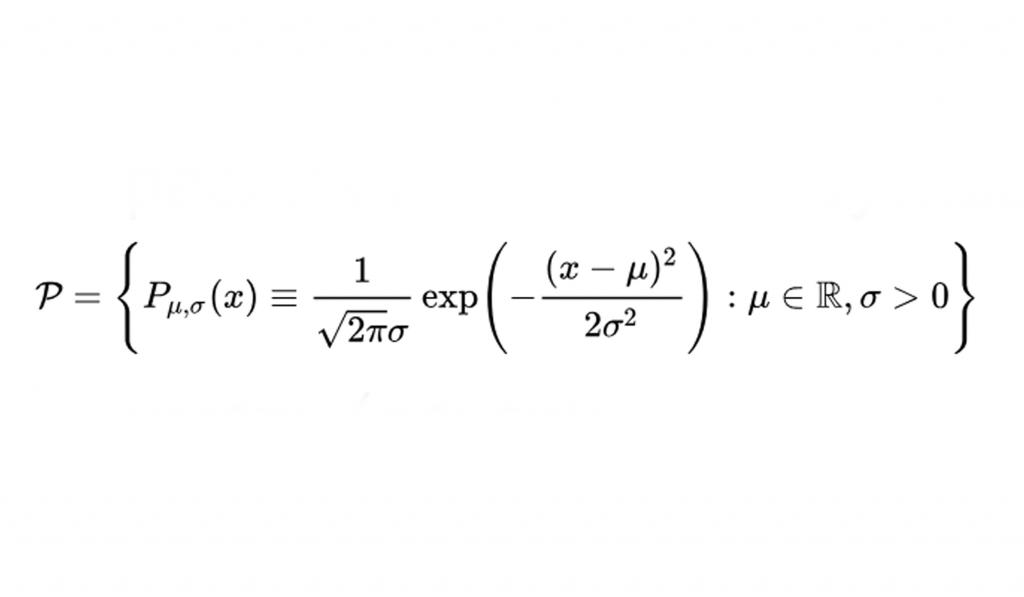
В этом примере размерность k равна 2.
А в качестве другого примера, можно предположить, что данные состоят из точек (x, y), которые, как предполагается, распределены по прямой линии с остатками Гаусса (с нулевым средним). Тогда размерность статистической экономической модели равна 3: пересечение линии, ее наклон и дисперсия распределения остатков. Необходимо обратить внимание, что в геометрии прямая линия имеет размерность 1.
Хотя вышеописанное значение формально является единственным параметром, который имеет размерность k, иногда он рассматривается как содержащий k отдельных значений. Например, с одномерным распределением Гаусса, О это единственный параметр с размером 2, но иногда рассматривается как содержащий два отдельных параметра — среднее значение и стандартное отклонение.
Статистическая модель процесса является непараметрической, если набор значений О бесконечномерен. А также она является полупараметрической, если имеет как конечномерные, так и бесконечномерные параметры. Формально, если k является размерностью О и n - число выборок, полупараметрические и непараметрические модели имеют
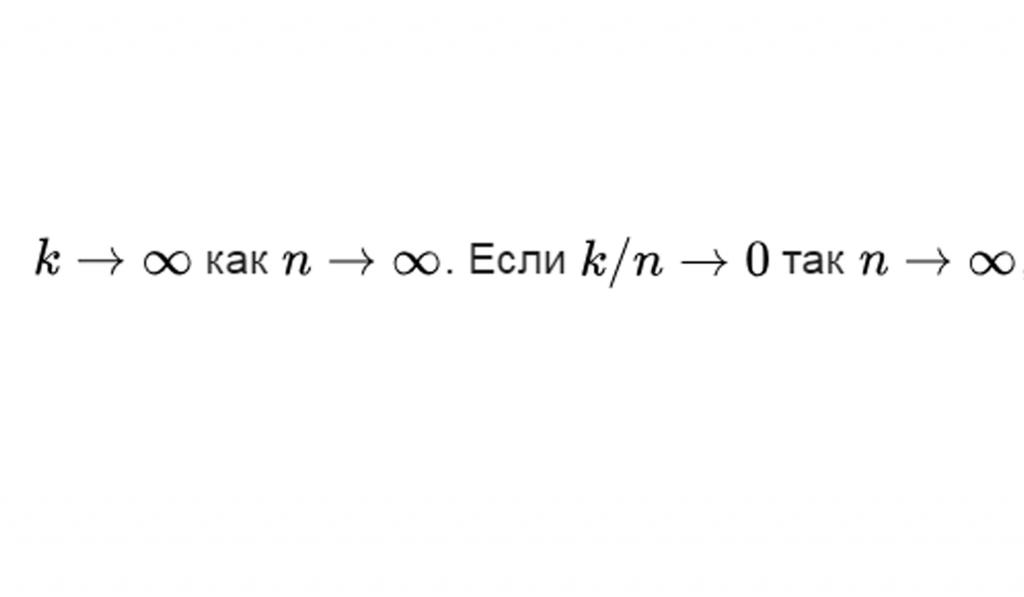
тогда модель является полупараметрической. В противном случае проекция является непараметрической.
Параметрические модели являются наиболее часто используемыми статистическими данными. Что касается полупараметрических и непараметрических проекций, сэр Дэвид Кокс заявил:
«Как правило, они подразумевают наименьшее число гипотез о текстуре и форме распределения, однако они включают мощные теории о самостоятельности».
Вложенные модели
Не стоит их путать с многоуровневыми проекциями.
Две статистические модели являются вложенными, если первую можно преобразовать во вторую путем наложения ограничений на параметры первой. Например, множество всех гауссовских распределений имеет вложенный в него набор распределений с нулевым средним:
То есть нужно ограничить среднее во множестве всех гауссовских распределений, чтобы получить распределения с нулевым средним. В качестве второго примера, квадратичная модель y = b 0 + b 1 x + b 2 x 2 + ε, ε ~N (0, σ2) имеет вложенную в нее линейную модель y = b0 + b1x + ε, ε ~ N (0, σ2) — то есть параметр b2 равен 0.
В обоих этих примерах первая модель имеет более высокую размерность, чем вторая модель. Такое часто, но не всегда бывает. В качестве другого примера можно привести множество гауссовых распределений с положительным средним, которое имеет размерность 2.
Сравнение моделей

Предполагается, что существует «истинное» распределение вероятности, лежащее в основе наблюдаемых данных, индуцированных процессом, который сгенерировал их.
А также модели можно сравнивать друг с другом, с помощью разведочного анализа или подтверждающего. В исследовательском разборе формулируются различные модели, и проводится оценка того, насколько хорошо каждый из них описывает данные. В подтверждающем анализе ранее сформулированная гипотеза сравнивается с исходной. Общие критерии для этого включают Р2, Байесовский фактор и относительную вероятность.
Мысль Кониши и Китагавы
«Большинство проблем статистической математической модели можно рассматривать как вопросы, связанные с прогнозированием. Они обычно формулируются как сравнения нескольких факторов».
Кроме того, сэр Дэвид Кокс сказал: «Как перевод из темы, проблема в статистической модели чаще всего является наиболее важной частью анализа».