Методы логистической регрессии и дискриминантного анализа используются тогда, когда необходимо четко дифференцировать респондентов по целевым категориям. При этом сами группы представлены уровнями одного одновариантного параметра. Рассмотрим далее подробно модель логистической регрессии, а также выясним, для чего она нужна.
Общие сведения
Примером задачи, в решении которой используется регрессия логистическая, может выступать классификация респондентов по группам покупающих и не покупающих горчицу. Дифференциация осуществляется в соответствии с социально-демографическими характеристиками. К ним, в частности, относят возраст, пол, количество родственников, доходы и пр. В операциях присутствуют критерии дифференциации и переменная. Последняя кодирует целевые категории, на которые, собственно, нужно разделить респондентов.
Нюансы
Следует сказать, что спектр случаев, в которых применяется регрессия логистическая, значительно уже, чем для дискриминантного анализа. В этой связи использование последнего как универсального способа дифференциации считается более предпочтительным. Более того, эксперты рекомендуют начинать классификационные исследования с дискриминантного анализа. И только в случае неуверенности за результаты можно использовать логистическую регрессию. Такая необходимость обуславливается некоторыми факторами. Регрессия логистическая используется при наличии четкого представления о типе независимых и зависимых переменных. В соответствии с этим выбирается одна из 3-х возможных процедур. При дискриминантном анализе исследователь всегда имеет дело с одной статической операцией. В ней участвует одна зависимая и несколько независимых категориальных переменных со шкалой любого типа.
Виды
Задача статистического исследования, в котором используется регрессия логистическая, состоит в определении вероятности того, что определенный респондент будет отнесен к той или иной группе. Дифференциация осуществляется по определенным параметрам. На практике, в соответствии со значениями одного либо нескольких независимых факторов, можно классифицировать респондентов по двум группам. В этом случае имеет место бинарная логистическая регрессия. Также заданные параметры могут использоваться при распределении на группы, которых больше двух. В такой ситуации имеет место мультиномиальная логистическая регрессия. Полученные группы выражены уровнями какой-то одной переменной.
Пример
Допустим, есть ответы респондентов на вопрос о том, интересно ли им предложение о приобретении земельного участка в пригороде Москвы. При этом даны варианты "нет" и "да". Необходимо выяснить, какие именно факторы оказывают преимущественное влияние на решение потенциальных покупателей. Для этого опрашиваемым задаются вопросы об инфраструктуре территории, расстоянии до столицы, площади участка, наличии/отсутствии жилого сооружения и пр. Используя бинарную регрессию, можно распределить респондентов по двум группам. В первую будут входить те, кто заинтересован в приобретении – потенциальные покупатели, а во вторую, соответственно, те, кого такое предложение не интересует. Для каждого респондента, кроме того, будет рассчитана вероятность отнесения к той или иной категории.
Сравнительная характеристика
Отличие от двух вариантов, указанных выше, состоит в различном числе групп и типе зависимых и независимых переменных. В бинарной регрессии, например, изучается зависимость дихотомического фактора от одного или нескольких независимых условий. При этом последние могут иметь любой тип шкалы. Мультиноминальная регрессия считается разновидностью этого варианта классификации. В ней к зависимой переменной относится больше 2-х групп. Независимые факторы должны иметь либо порядковую, либо номинальную шкалу.
Логистическая регрессия в spss
В статистическом пакете 11-12 был введен новый вариант анализа – порядковый. Этот метод используется в случае, когда зависимый фактор относится к одноименной (порядковой) шкале. При этом независимые переменные выбираются одного определенного типа. Они должны быть или порядковыми, или номинальными. Классификация по нескольким категориям считается наиболее универсальной. Этот способ может использоваться во всех исследованиях, в которых применяется логистическая регрессия. Повысить качество модели, однако, можно только с помощью всех трех приемов.
Порядковая классификация
Стоит сказать, что ранее в статистическом пакете не была предусмотрена типовая возможность выполнения специализированного анализа для зависимых факторов с порядковой шкалой. Для всех переменных с количеством групп больше 2-х использовался мультиноминальный вариант. Введенный относительно недавно порядковый анализ обладает рядом особенностей. Они учитывают именно специфику шкалы. Между тем в методических пособиях порядковая логистическая регрессия часто не рассматривается как отдельный прием. Обусловлено это следующим: порядковый анализ не обладает какими-либо значительными преимуществами перед мультиноминальным. Исследователь вполне может использовать последний при наличии и порядковой, и номинальной зависимой переменной. При этом сами процессы классификации почти не отличаются друг от друга. Это означает, что проведение порядкового анализа не вызовет каких-либо сложностей.
Вариант анализа
Рассмотрим простой случай – бинарную регрессию. Допустим, в процессе маркетингового исследования оценивается востребованность выпускников определенного столичного вуза. В анкете респондентам предложены вопросы, в числе которых:
- Являетесь ли вы работающим? (ql).
- Укажите год окончания вуза (q 21).
- Каков средний выпускной балл (aver).
- Пол (q22).
Логистическая регрессия позволит оценить воздействие независимых факторов aver, q 21 и q 22 на переменную ql. Проще говоря, целью анализа будет определение вероятного трудоустройства выпускников на основании сведений о поле, годе окончания и среднего балла.
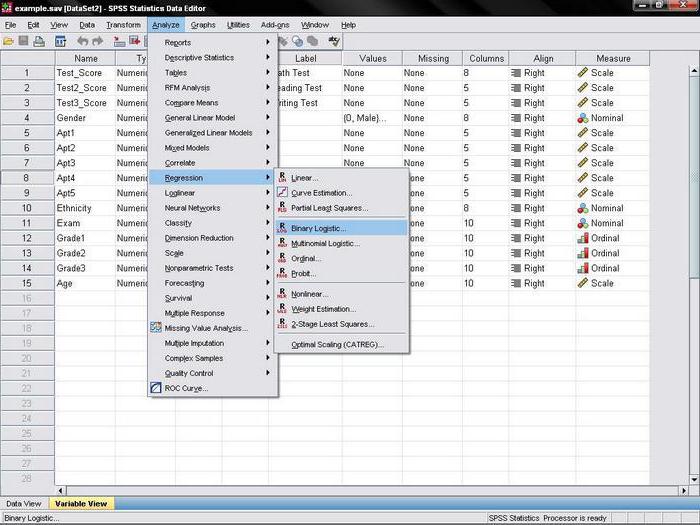
Logistic Regression
Чтобы задать параметры с помощью бинарной регрессии, следует воспользоваться меню Analyze►Regression►Binary Logistic. В окне Logistic Regression нужно выбрать в левом списке доступных переменных зависимый фактор. Им является ql. Эту переменную нужно поместить в поле Dependent. После этого на участок Covariates необходимо ввести независимые факторы – q 21, q 22, aver. Затем нужно выбрать способ их включения в анализ. Если количество независимых факторов больше 2-х, используется не метод одновременного введения всех переменных, который установлен по умолчанию, а пошаговый. Самым популярным способом считается Backward:LR. Используя кнопку Select, можно включить в исследование не всех респондентов, а только конкретную целевую категорию.
Define Categorical Variables
Кнопку Categorical нужно использовать в том случае, когда одной из независимых переменных является номинальная с количеством категорий больше 2-х. В этой ситуации в окне Define Categorical Variables на участок Categorical Covariates помещается именно такой параметр. В рассматриваемом примере такая переменная отсутствует. После этого в раскрывающемся перечне Contrast следует выбрать пункт Deviation и нажать кнопку Change. В итоге из каждого номинального фактора будет сформировано несколько зависимых переменных. Их количество соответствует числу категорий исходного условия.
Save New Variables
С помощью кнопки Save в основном диалоговом окне исследования задается создание новых параметров. Они будут содержать показатели, рассчитанные в процессе регрессии. В частности, можно создать переменные, которыми определяются:
- Принадлежность к конкретной категории классификации (Groupmembership).
- Вероятность отнесения респондента в каждую исследуемую группу (Probabilities).
При использовании кнопки Options исследователь не получает каких-либо существенных возможностей. Соответственно, ее можно игнорировать. После нажатия кнопки "Ок" в основном окне будут выведены результаты анализа.
Проверка качества адекватностии логистической регрессии
Рассмотрим таблицу Omnibus Testsof Model Coefficients. В ней отображаются результаты анализа качества приближения модели. В связи с тем, что был задан пошаговый вариант, нужно смотреть итоги последнего этапа (Step2). Положительным будет считаться такой результат, при котором обнаруживается увеличение показателя Chi-square при переходе на следующую стадию при высокой степени значимости (Sig. < 0,05). Качество модели оценивается в строке Model. Если получена отрицательная величина, но она не рассматривается как значимая при общей высокой существенности модели, последнюю можно признать практически пригодной.
Таблицы
Model Summary дает возможность оценить показатель совокупной дисперсии, которую описывает построенная модель (показатель R Square). Рекомендуется применять величину Nagelker. Положительным показателем можно считать параметр Nagelkerke R Square, если он выше 0.50. После этого оцениваются результаты классификации, в которой действительные показатели принадлежности к той либо другой исследуемой категории сравниваются с предсказанными на основе регрессионной модели. Для этого используется таблица Classification Table. Она также позволяет сделать выводы о корректности дифференциации для каждой рассматриваемой группы.
Первая таблица, в которой присутствуют важные для исследователя показатели, – Model Fitting Information. Высокий уровень статистической значимости будет указывать на высокое качество и пригодность использования модели при решении практических задач. Еще одной значимой таблицей является Pseudo R-Square. Она позволяет оценить долю общей дисперсии в зависимом факторе, которая обуславливается независимыми переменными, выбранными для анализа. По таблице Likelihood Ratio Tests можно сделать выводы о статистической значимости последних. В Parameter Estimates отражаются нестандартизированные коэффициенты. Они используются при построении уравнения. Кроме этого, для каждого сочетания переменных определена статистическая значимость их воздействия на зависимый фактор. Между тем в маркетинговых исследованиях зачастую возникает необходимость дифференцировать по категориям респондентов не по отдельности, а в составе целевой группы. Для этого используется таблица Observedand Predicted Frequencies.
Практическое применение
Рассмотренный способ анализа широко используется в работе трейдеров. В 1991 г. был разработан индикатор логистической сигмовидной регрессии. Он представляет собой простой в эксплуатации и эффективный инструмент, с помощью которого можно спрогнозировать вероятные цены до их "перегрева". Индикатор представлен на графике в виде канала, образованного двумя линиями, проходящими параллельно. Они удалены на равное расстояние от тренда. Ширина коридора будет зависеть исключительно от таймфрейма. Индикатор используется при работе почти со всеми активами – от валютных пар до драгметаллов.
На практике выработано 2 ключевые стратегии применения инструмента: на пробой и на разворот. В последнем случае трейдер будет ориентироваться на динамику ценового изменения в пределах канала. По мере приближения стоимости к линии поддержки или сопротивления ставка делается на вероятность того, что движение начнется в обратном направлении. Если цена вплотную подойдет к верхней границе, то от актива можно избавиться. Если же она находится у нижнего предела, то стоит задуматься о приобретении. Стратегия на пробой предполагает применение ордеров. Они устанавливаются за границами пределов на относительно небольшом удалении. Принимая во внимание, что цена в ряде случаев нарушает их на непродолжительное время, следует перестраховаться и установить стоп-лоссы. При этом, разумеется, независимо от выбранной стратегии трейдеру необходимо максимально хладнокровно воспринимать и оценивать ситуацию, возникшую на рынке.
Заключение
Таким образом, применение логистической регрессии позволяет быстро и просто классифицировать респондентов на категории в соответствии с заданными параметрами. При анализе можно использовать какой-либо определенный способ. В частности, универсальностью отличается мультиноминальная регрессия. Однако специалисты рекомендуют применять все описанные выше способы в комплексе. Это обуславливается тем, что в таком случае качество модели будет существенно выше. Это, в свою очередь, расширит спектр ее применения.