














Кодирование звука относится к способам сохранения и передачи аудиоданных. В приведенной ниже статье описывается, как работают такие кодировки.
Заметим, что это довольно сложная тема - "Глубина кодирования звука". Определение данного понятия также будет дано в нашей статье. Представленные в статье концепции предназначены только для общего обзора. Раскроем понятия глубины кодирования звука. Некоторые из этих справочных данных могут быть полезны для понимания того, как работает API, а также как формулировать и обрабатывать аудио в ваших приложениях.
Как найти глубину кодирования звука
Аудиоформат не эквивалентен аудиокодированию. Например, популярный формат файла, такой как WAV, определяет формат заголовка аудиофайла, но сам по себе не является кодировкой звука. WAV-аудиофайлы часто, но не всегда используют линейную кодировку PCM.
В свою очередь, FLAC является как форматом файла, так и кодировкой, что иногда приводит к некоторой путанице. В пределах Speech API FLAC глубина кодирования звука — это единственная кодировка, которая требует, чтобы аудиоданные включали заголовок. Все другие кодировки указывают беззвучные аудиоданные. Когда мы ссылаемся на FLAC в Speech API, мы всегда ссылаемся на кодек. Когда мы ссылаемся на формат файла FLAC, мы будем использовать формат «.FLAC».

Вы не обязаны указывать кодировку и частоту дискретизации для файлов WAV или FLAC. Если этот параметр опущен, API облачной речи автоматически определяет кодировку и частоту дискретизации для файлов WAV или FLAC на основе заголовка файла. Если вы укажете значение кодировки или частоты дискретизации, которое не соответствует значению в заголовке файла, API облачной речи вернет ошибку.
Глубина кодирования звука — это что такое?
Аудио состоит из осциллограмм, состоящих из интерполяции волн разных частот и амплитуд. Чтобы представить эти формы сигналов в цифровых средах, сигналы должны быть отбракованы со скоростью, которая может представлять звуки самой высокой частоты, которые вы хотите воспроизвести. Для них также необходимо хранить достаточную глубину бит для представления правильной амплитуды (громкость и мягкость) осциллограмм по образцу звука.
Способность устройства звуковой обработки воссоздавать частоты известна как его частотная характеристика, а способность создавать надлежащую громкость и мягкость известна как динамический диапазон. Вместе эти термины часто называют верностью звукового устройства. Глубина кодирования звука — это средство, с помощью которого можно восстановить звук, используя эти два основных принципа, а также возможность эффективно хранить и передавать такие данные.
Частота выборки
Звук существует как аналоговая волновая форма. Сегмент цифрового звука аппроксимирует эту аналоговую волну и сэмплирует ее амплитуду с достаточно высокой скоростью, чтобы имитировать собственные частоты волны. Частота дискретизации цифрового аудиосигнала определяет количество выборок, взятых из исходного материала аудио (в секунду). Высокая частота дискретизации увеличивает способность цифрового звука точно представлять высокие частоты.

Как следствие теоремы Найквиста-Шеннона, обычно нужно пробовать хотя бы вдвое большую частоту любой звуковой волны, которую необходимо записать в цифровом виде. Например, для представления звука в диапазоне человеческого слуха (20-20000 Гц), цифровой аудиоформат должен отображать не менее 40000 раз в секунду (что является причиной того, что звук CD использует частоту дискретизации 44100 Гц).
Бит глубины
Глубина кодирования звука — это влияние на динамический диапазон заданного образца звука. Более высокая битовая глубина позволяет представлять более точные амплитуды. Если у вас много громких и мягких звуков в одном и том же звуковом образце, вам понадобится больше бит, чтобы правильно передавать эти звуки.
Более высокие битовые глубины также уменьшают соотношение "сигнал/шум" в образцах аудио. Если глубина кодирования звука составляет 16 битов, музыкальный звук CD передается с использованием данных величин. Некоторые методы сжатия могут компенсировать меньшие битовые глубины, но они, как правило, являются потерями. DVD Audio использует 24 бит глубины, в то время как в большинстве телефонов глубина кодирования звука составляет 8 бит.
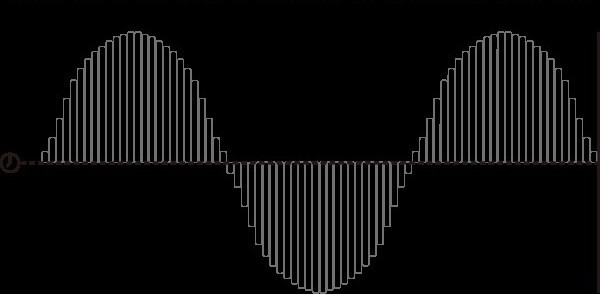
Несжатый звук
Большая часть обработки цифрового звука использует эти два метода (частоту дискретизации и глубину бит) для простого хранения аудиоданных. Одна из самых популярных технологий цифрового звука (популяризированная при использовании компакт-диска) известна как модуляция импульсного кода (или PCM). Аудио выбирается с установленными интервалами, и амплитуда дискретизированной волны в этой точке сохраняется как цифровое значение с использованием битовой глубины образца.
Линейный PCM (который указывает, что амплитудный отклик является линейно однородным по выборке) является стандартом, используемым на компакт-дисках и в кодировке LINEAR16 Speech API. Оба кодирования создают несжатый поток байтов, соответствующий непосредственно аудиоданным, и оба стандарта содержат 16 бит глубины. Линейный PCM использует частоту дискретизации 44 100 Гц на компакт-дисках, что подходит для перекомпоновки музыки. Однако частота дискретизации 16000 Гц более подходит для рекомпозиции речи.
Линейный PCM (LINEAR16) является примером несжатого звука, поскольку цифровые данные хранятся аналогичным образом. При чтении одноканального потока байтов, закодированного с использованием Linear PCM, вы можете подсчитать каждые 16 бит (2 байта) для получения другого значения амплитуды сигнала. Практически все устройства могут манипулировать такими цифровыми данными изначально — можно обрезать аудиофайлы Linear PCM с помощью текстового редактора, но несжатый звук - не самый эффективный способ транспортировки или хранения цифрового звука. По этой причине большинство аудио использует цифровые методы сжатия.
Сжатый звук
Аудиоданные, как и все данные, часто сжимаются, что облегчает их хранение и транспортировку. Сжатие в аудиокодировании может происходить либо без потерь, либо с потерями. Сжатие без потерь можно распаковать, чтобы восстановить цифровые данные в исходную форму. Сжатие обязательно удаляет некоторую информацию во время процедуры декомпрессии и параметризуется, чтобы указать степень толерантности к технике сжатия для удаления данных.
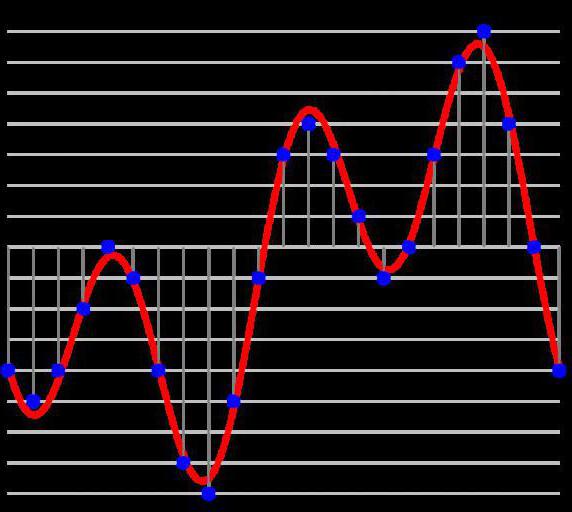
Без потерь
Без потерь сжимаются цифровые аудиозаписи, используя сложные перестановки сохраненных данных, что не приводит к ухудшению качества исходного цифрового образца. При сжатии без потерь при распаковке данных в исходную цифровую форму информация не будет потеряна.
Итак, почему методы сжатия без потерь иногда имеют параметры оптимизации? Эти параметры часто обрабатывают размер файла для времени декомпрессии. Например, FLAC использует параметр уровня сжатия от 0 (самый быстрый) до 8 (наименьший размер файла). Сжатие FLAC более высокого уровня не потеряет никакой информации по сравнению со сжатием более низкого уровня. Вместо этого алгоритму сжатия просто нужно будет затрачивать больше вычислительной энергии при построении или деконструировании оригинального цифрового звука.
API Speech поддерживает два кодирования без потерь: FLAC и LINEAR16. Технически LINEAR16 не является «сжатием без потерь», поскольку в первую очередь не задействовано сжатие. Если размер файла или передача данных важны для вас, выберите FLAC как ваш вариант кодирования звука.
Потеря компрессии
Сжатие аудиоданных устраняет или уменьшает некоторые типы информации при построении сжатых данных. Speech API поддерживает несколько форматов с потерями, хотя их следует избегать, поскольку потеря данных может повлиять на точность распознавания.
Популярный MP3-кодек является примером метода кодирования с потерями. Все методы сжатия MP3 удаляют звук извне обычного аудиодиапазона человека и регулируют уровень сжатия, регулируя эффективную скорость передачи данных кодека MP3 или количество бит в секунду для сохранения даты звука.
Например, стерео CD с использованием линейного PCM из 16 бит имеет эффективную скорость передачи битов. Формула глубины кодирования звука:
441000 * 2 канала * 16 бит = 1411200 бит в секунду (бит/с) = 1411 Кбит/с
Например, сжатие MP3 удаляет такие цифровые данные, используя скорость передачи данных, такие как 320 кбит/с, 128 кбит/с или 96 кбит/с, что приводит к ухудшению качества звука. MP3 также поддерживает переменные скорости передачи битов, которые могут дополнительно сжать аудио. Оба метода теряют информацию и могут влиять на качество. С уверенностью можно сказать, что большинство людей могут определить разницу между кодированной MP3-музыкой 96 кбит/с или 128 Кбит/с.

Другие формы сжатия
MULAW — это 8-битное кодирование PCM, где амплитуда выборки модулируется логарифмически, а не линейно. В результате uLaw уменьшает эффективный динамический диапазон сжатого звука. Хотя uLaw был введен специально для оптимизации кодирования речи в отличие от других типов аудио, 16-битный LINEAR16 (несжатый PCM) по-прежнему намного превосходит 8-битный сжатый звук uLaw.
AMR и AMR_WB модулируют кодированный аудиокасс, вводя переменную скорость передачи битов в исходный звуковой образец.
Хотя Speech API поддерживает несколько форматов с потерями, вам следует избегать их, если у вас есть контроль над исходным аудио. Хотя удаление таких данных посредством сжатия с потерями может не оказывать заметного влияния на звук, слышимый человеческим ухом, потеря таких данных для механизма распознавания речи может значительно ухудшить точность.











